In February 2007, DDBJ replaced the computer system and upgraded some of the application programs. In the meantime, DDBJ has been required to process millions of entries. The question here is if the new system has been able to satisfy the emerging requirements.
You might recognize that you can hold your entries in a certain period or until the relevant paper are published. DDBJ should not disclose these Hold-Until-Published entries to the public. To retain them inside DDBJ, DDBJ stores these entries in a separate server from servers for data dissemination, e.g. getentry server.
In the daily data release procedure shown in the following figure, DDBJ convert entries into the flat file format from the server for in-house data management to transfer them to other servers for such services to the public as getentry, ARSA, homology search and anonymous FTP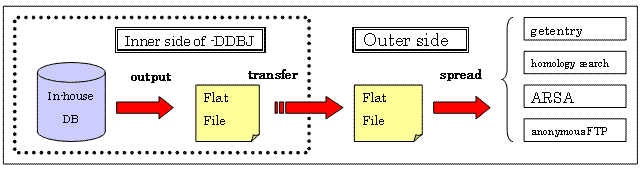
This month (January 2008), DDBJ released about 1,500,000 entries only in two days; about 1,000,000 entries in the first day, and about 500,000 entries in the second day. It is to be noted that this process was completed as smoothly as designed. With the previous system, we were able to process only 350,000 entries in a day, namely, we had to spend more than 4 days to complete 1.5M entries.
Although the mission was completed this time, we learned some lessons to improve the procedure further. You may claim that “2 days” is not quick enough. The system engineers in charge started the discussion to improve the concordance of several servers to gain higher throughput than ever.
We would appreciate it very much, if you remember the group of hard working system engineers especially when you see the announcement of massive data release.