BioProject
プロジェクトの登録
プライマリーとアンブレラ
プロジェクトにはプライマリーとアンブレラの二種類があります。
- プライマリープロジェクト
- 既に登録したデータ、または、これから登録しようとしているデータをまとめるために登録者が作成するプロジェクト。関連するデータが公開されるまで非公開にすることができます。
- アンブレラプロジェクト
-
関連性のあるプロジェクトを上位でまとめるプロジェクト。アンブレラプロジェクトは非公開にすることはできません。
- 登録データはプライマリープロジェクトを直接参照することができますが、アンブレラプロジェクトを直接参照することはできません。
階層構造
大規模プロジェクトを1つ以上の階層で表すことができます。最上位で共同研究プロジェクト全体を表し、二階層目で各機関が分担しているプロジェクトに対応するアンブレラプロジェクトを作成し、最後の三段目で実験データから参照されるプライマリープロジェクトを作成する、といった構成です。プライマリーとアンブレラプロジェクトは複数のアンブレラプロジェクトを参照することができます。

プロジェクトが必要な場合
プロジェクトが必要かどうかは登録ナビゲーションで確認してください。
新規登録
DDBJ アカウントを取得します。
D-way にログインします。上部メニューから BioProject 登録ページに移動します。BioProject ページ内の [New submission] で新規登録を作成します。
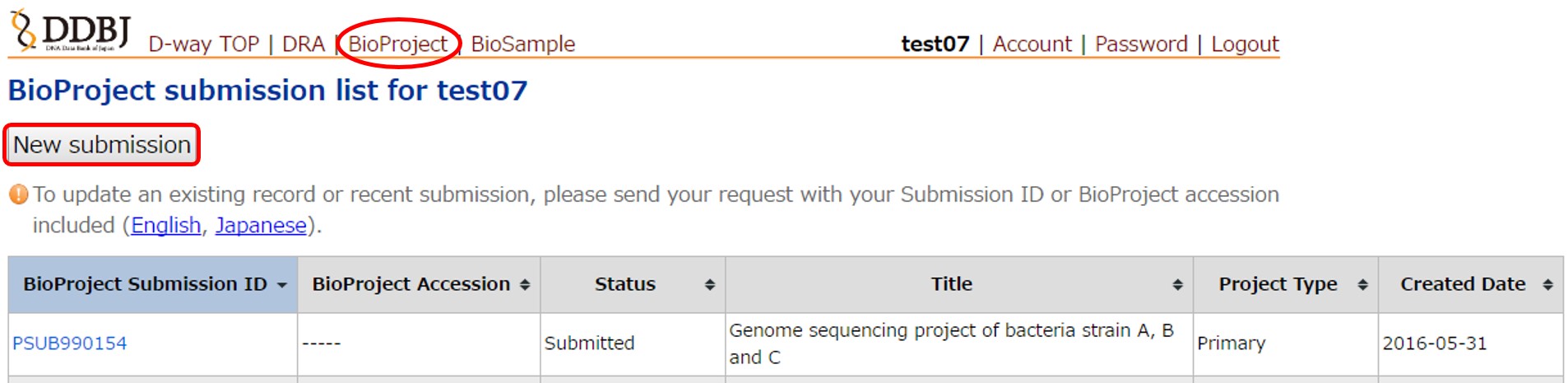
左のタブから順番に内容を英語で入力していきます。BioProject 入力項目の説明
アノテーションが付与されたゲノム配列を DDBJ に登録する場合、
locus tag prefix を BioSampleで登録します。
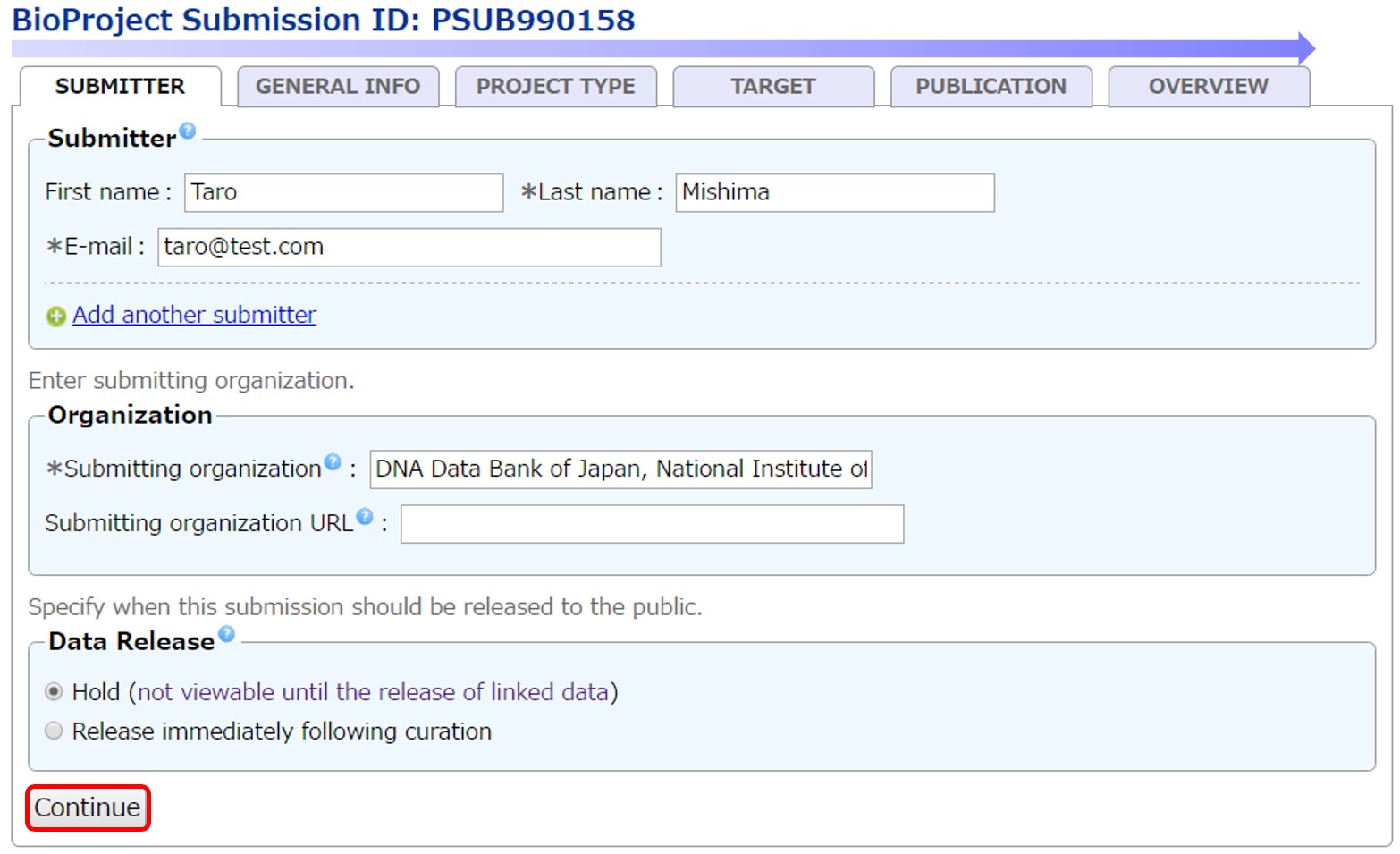
最後の “OVERVIEW” で内容を確認したうえで [Submit] で登録します。
アクセッション番号
登録されたプロジェクトに対して、プレフィックス “PRJDB” のアクセッション番号が自動で発行されます。 即日公開 (Release immediately following curation) が指定されている場合、登録された日の夜間に自動公開されます。
- PSUB で始まる仮 ID を論文中に引用しないでください。
- EBI/NCBI に登録したプロジェクトを DDBJ に重複して登録しないでください。
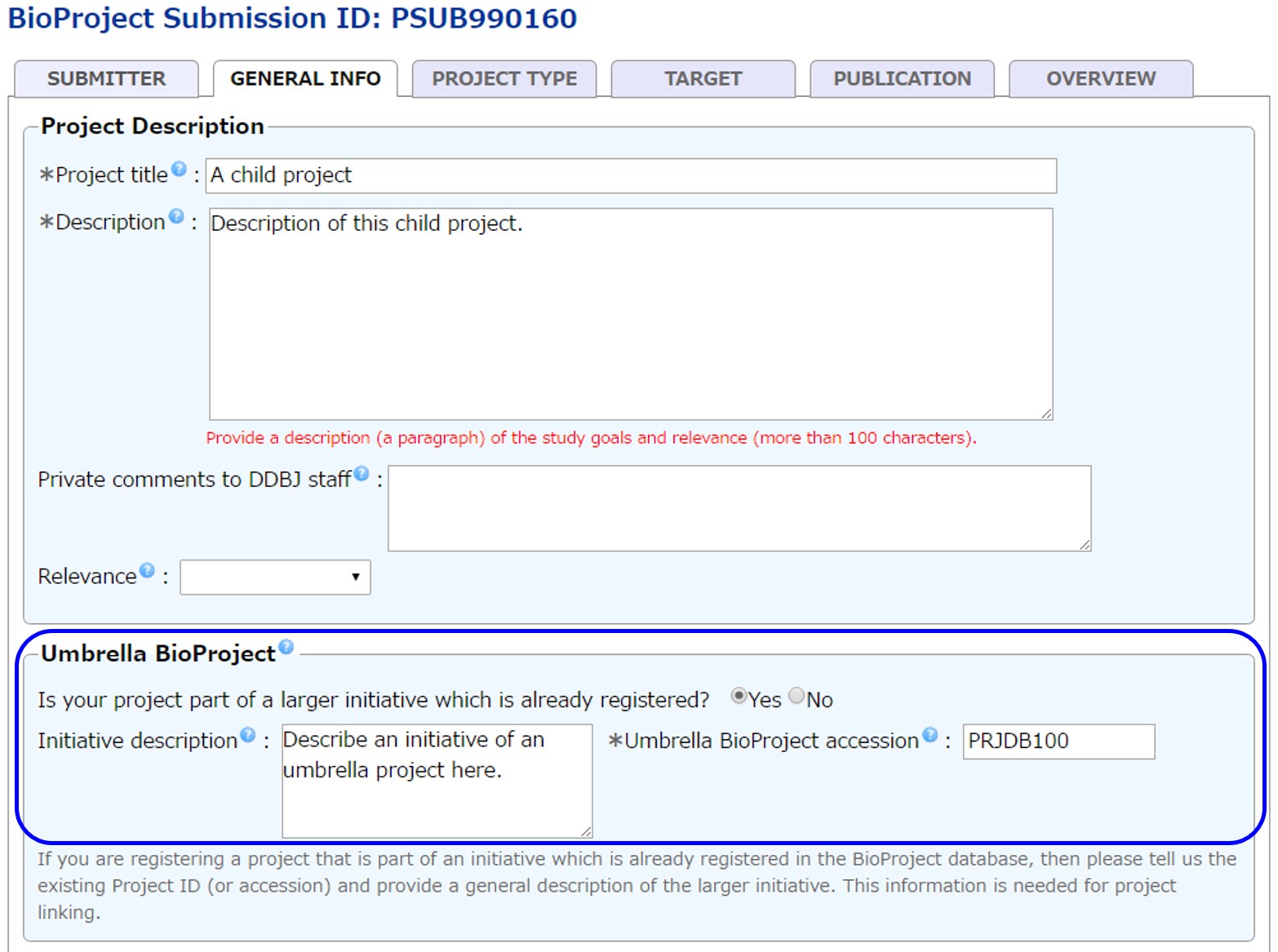
アンブレラプロジェクトの登録
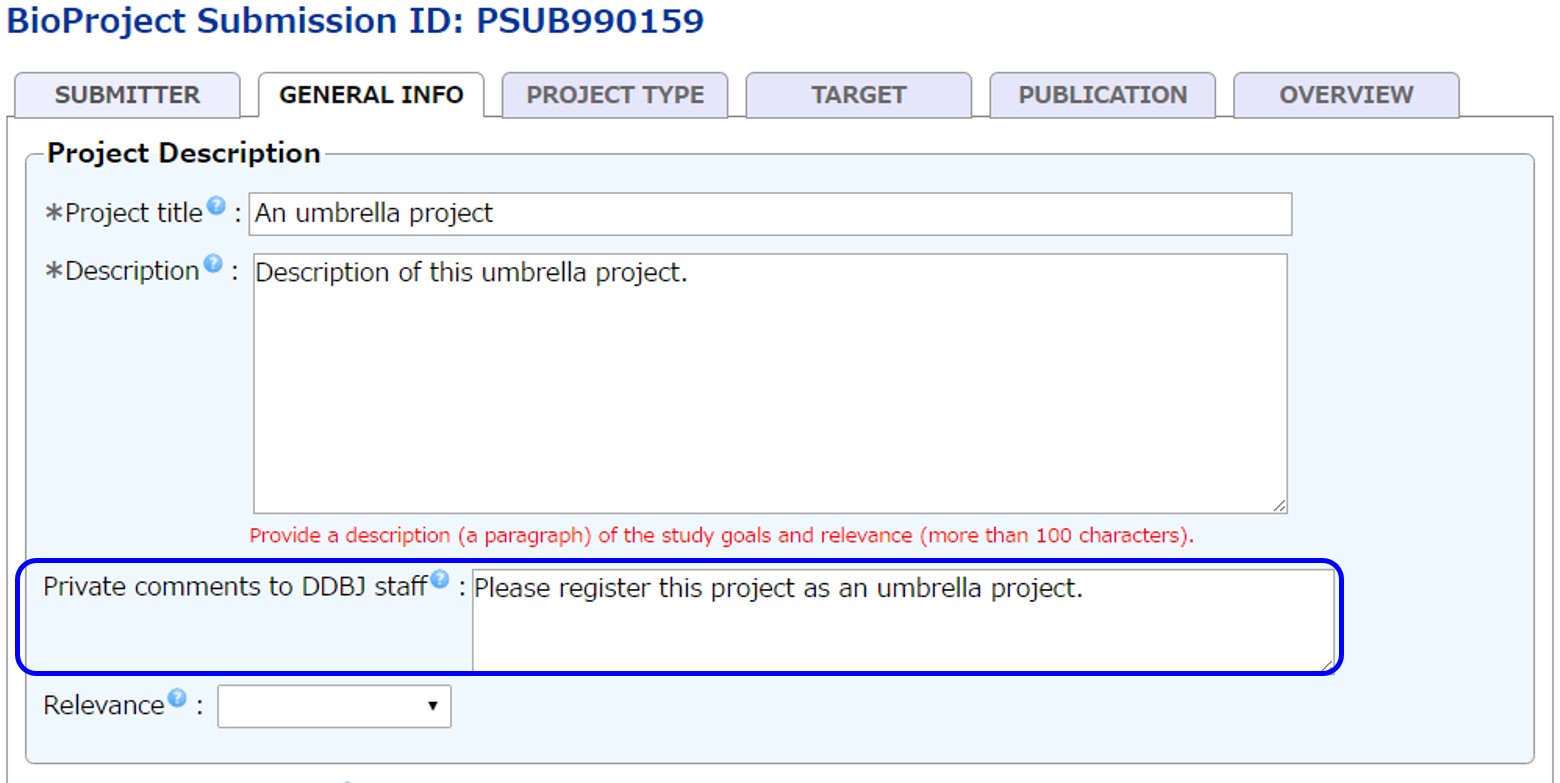
アンブレラプロジェクトは通常のプライマリープロジェクトと同様 D-way から登録します。 登録の際には必ず Private comments to DDBJ staff にこの登録がアンブレラであることを記入してください。 アンブレラプロジェクトを非公開にすることはできません。
Haplotype をまとまるアンブレラプロジェクトを登録する場合、配下にリンクするプライマリープロジェクトのアクセッション番号とその区別 (例 PRJDB1 Principal, PRJDB2 Alternate, PRJDB3 DRA) を記入します。
アンブレラプロジェクトへのリンク
プライマリープロジェクトを登録する際、Umbrella BioProject にリンクすべきアンブレラプロジェクトのアクセッション番号を記入します。BioProject スタッフは記入内容をみて、プロジェクトをアンブレラにリンクする作業を行います。
ヒトデータの登録
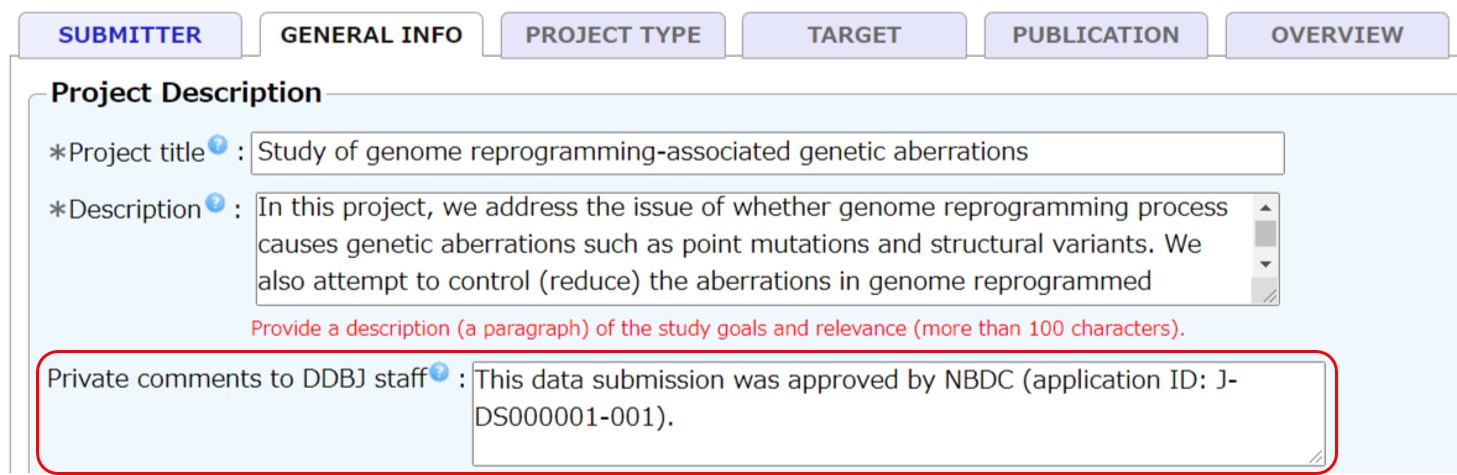
ヒトデータを DRA/GEA/DDBJ へ登録するためには、DBCLS に登録予定データの提供申請を提出し、承認されている必要があります。詳しくはヒトを対象とした研究データの登録についてをご覧ください。
承認されている場合、BioProject の「Private comments to DDBJ staff」に提供申請 ID (例 J-DS000001-001) を記入します。
プロジェクトの公開
以下のいずれかを選択します。公開予定日は設定できません。
- 登録完了後、すぐに公開
- BioProject アクセッション番号を引用しているデータと同時に公開
登録したプロジェクトは非公開にすることができます。公開の仕組みは以下になります。
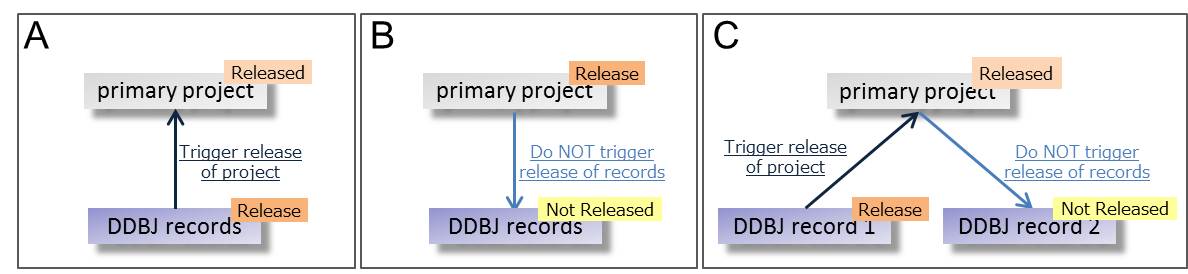
- BioProject に登録されたプライマリープロジェクトは「即日公開」もしくは「非公開」にすることができます。
- 「非公開」の場合、登録されたプライマリープロジェクトは参照されている DDBJ/DRA/GEA/MetaboBank データが公開されるまで非公開に保たれます。
- プロジェクトデータの公開予定日を設定することはできません。
- プライマリープロジェクトは参照されている DDBJ/DRA/GEA/MetaboBank データが公開されると自動的に連動公開されます。
- プライマリープロジェクトの公開は当該プロジェクトを参照している DDBJ/DRA/GEA/MetaboBank データの公開を引き起こしません。
- プライマリープロジェクトを参照しているデータの公開は当該プロジェクトに属している他のデータの公開を引き起こしません。
FAQ: BioProject/BioSample/塩基配列データの連動公開の仕組みは?
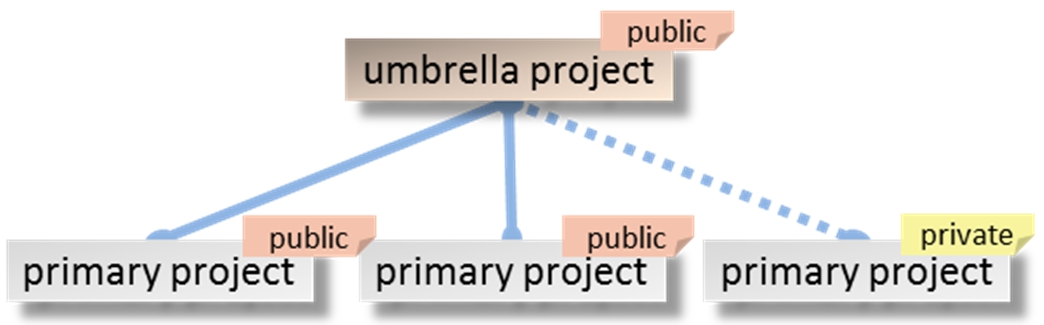
アンブレラプロジェクトは非公開にすることができません。
アンブレラプロジェクトは公開されているプライマリープロジェクトと非公開のプロジェクトの両方を持つことができます。第三者は公開されているアンブレラプロジェクトと非公開のプライマリープロジェクト間の関係を見ることはできません。
公開されたプロジェクトデータは NCBI と EBI の BioProject と交換されます。
プロジェクトの更新
論文情報の追加など、登録が完了したプロジェクトを更新することができます。DDBJ BioProject で更新しますので、BioProject/BioSample/DRA 更新依頼フォームから更新を依頼してください。