DDBJ アノテータの業務紹介
ユーザーの皆様に DDBJ について業務内容を知って頂きより身近に感じていただけるよう,DDBJ アノテータが DDBJ Mail Magazine にリレー連載したコラムをまとめました。
連載期間:No.55(2010年12月1日発行)〜No.65(2011年10月27日発行)※最新の情報とは内容が異なる場合がありますのでご注意下さい。
1.Primary Database を維持するということ(前編/後編)
DDBJ チーフアノテータ 真島 淳
自己紹介みたいなものは興味のある場合だけ, 過去の雑文を読んでいただくことに代えて割愛します。 ただ, 当時と違い今は chief でも, annotator でもないという説もあります。 それでも, 現場ではエラそうに仕切っているという不思議な感じにしています。
今回は リレー連載形式で DDBJ annotator の業務を紹介するという主旨で枠を割いてもらい, その最初を任されました。どのように書くべきかには迷いましたが, 細かい仕事の実際は他のメンバーに任せて, 古株っぽく理念のようなものについて, 整理してみましょう。 堅苦しくならないように, 書いていきます。
1.DDBJ の抱える primary database 特有の事情
「INSDC は primary database を構築している」という主張は GenBank (NCBI) と EMBL-Bank (ENA/EBI) との対話において頻出しますが, 今一つ一般的には浸透していません。 primary database とは, おそらく一般には「個々の研究者が自らデータを登録する仕組みで収集されたデータベース」というようなことを指すと思います。DDBJ におけるデータのサイクルを図に示しています。
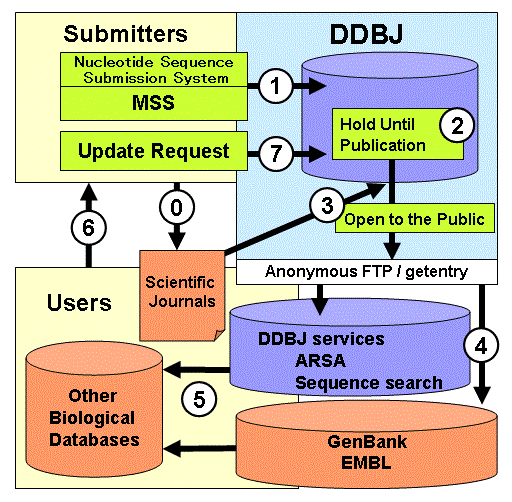

primary database の場合, そのコンテンツに関する responsibility とか, 文責のようなものは, 本来, 登録した個々の研究者に帰せられるべきです。 よく混同される RefSeq を対照例にします。 RefSeq は NCBI が独自に構築しており secondary database に相当します。 対して DDBJ/EMBL-Bank/GenBank は一般の研究者が決めた塩基配列を受け付ける primary database に相当します。 RefSeq は実は DDBJ/EMBL-Bank/GenBank から引用, 冗長性をなくすような選択, NCBI の staff による記述の見直しと修正などを経て構築されています。この特定 staff が自由に記述を改訂することが可能か否かの点が primary database と secondary database で大きく異なります。 RefSeq の FAQ 項目で説明されていますが, この文脈では GenBank と DDBJ, EMBL-Bank は等価ですので, 読み替えてください。
生命情報の分野には多数のデータベースが存在しますが, その多くは secondary database か, あるいは, 自身のデータを整理するといった対象を限定したデータベースに相当します。 secondary database は書式・判断基準などの制御が容易ですので, 目的に合致した形式で よく整理されていれば, primary database を直接検索するよりも効率が良いケースも多 と思います。 しかし, primary database なしには, secondary database は存在し得ません。
時折, DDBJ にいただく意見に primary database としてのデータベース, または, そのコンテンツの性格をご理解いただいていないと感じることがあります。 例えば, データの間違いを指摘しても直らない, といった批判があります。しかし, そのデ タの登録者が不誠実なのか, データベース管理者が登録者に伝えることができないのか, 批判している人物の指摘が妥当ではないのか, 要因別に責任の所在が異なります。 primary database の場合には, データベース管理者の責任とかデータベースの欠点というより, 事業の性格と理解・許容すべき点もあるではないかと思います。 そういえば, DDBJ が primary database である, という根本的な説明を記載する機会にも恵まれていなかったような気がします。
この分野では primary database として成功している実例の1つに wwPDB がありますが, データ量を議論したとき, INSDC に匹敵するものは, まずないと思います。 INSDC のデータは蓄積量も確かに膨大ですし, 日々の処理も それなりに多いのです。更に, もし, 個々の研究者から送られてくるデータを何もせずに置いておけば良いのでしたら運営も非常に楽なのですが, 実際はモロモロの理由から, それでは済みません。 primary database もデータベースですから, データが書式に則っていないと差し障りがあります。
2. DDBJ, すなわち primary database としての INSDCへの登録
ここで やっと annotator の業務の話になるのですが, DDBJ においては「国内外の一般研究者から送られてくる塩基配列とその付帯情報を公開可能な状態に整える作業」であり, これを「査定業務」と称しています。 この定義文のような文章は, 数年前に私が何かの書類提出用に業務を説明するために書きましたが, ほぼ そのまま使われていました。 もっとも DDBJ は, 20 年以上前から primary database を運営してますから, こんな文言が私が書く以前にはなかったことが不思議です。当たり前のように感じている活動の言語化は意外に難しいのかもしれません。 「査定」の英語が annotation で それをする人が annotator です。 ちなみに GenBank では同じような職種を indexer, EMBL-Bank では curator と呼んでいます。 DDBJ における「査定」を総括すると 登録者から送られてくる情報を 1) データベース記載規則に則る形式で 2) 登録者の意図する記載を 3) 正確に反映すること となるでしょうか。しかし, これが意外と難度の高い場面があります。
登録者側では, 面倒な「データベース記載規則」など, 読み下すことは困難でしょうし, 最終記載を意識しながら, データ入力するといった作業は, 結構, 厄介です。 特殊な単語が頻出しますから, スペルチェックも大変です。学名の間違いなども日常茶飯事です。 また, 塩基配列決定が身近になり過ぎたこともあり, 登録をする人が生物学を知らない職種にまで広がり, 記載を読んでも疑問符で, 結局, メールで問い合わせて謎が解けるといったことも多々あります。 クダらないと感じるような修正・訂正から 非常に高度な生物学的過程の記述法に悩むレベルまで, 様々ですが, いつも登録者とメールして解決を図っています。
生命情報分野の大御所の某センセイが, DDBJ は GenBank をミラーしているだけ, という主旨のことを現場も見ずに書いていますが, 実際には結構, いろいろな仕事を annotator も他の職種の人もしています。 ただ, 内部からは逆に, annotator は 細かい修正などせず, もっと登録者の自己責任と割り切って効率化を図れ, とも言われているのです。 primary database も, ある程度は正確さとか, 品質とかを保つ努力は必要でしょうが, バランスの難しいところがあります。
3.需要に応えるために拡張してきた INSDC の歴史
実は, 英語が苦手な私が NCBI や EBI の仕事仲間たちと毎年 meeting して, 英語で discussion し, 比較的頻繁にメールし合うということも思えば不思議な縁です。
一般には, なかなか理解してもらえない feature とか qualifier の拡張・統廃合は, 毎年, 議論されます。 2007 年と少し前になりますが, 過去の象徴的な事例を 拙稿 (署名していませんが): RNA ワールドへの対応にまとめています。 RNA ワールドと言っても化学進化の類の意ではありません。miRNA などに代表されるタンパク質コードの伝令を担わない RNA 産物の記載需要が増えた時期と ncRNA feature 導入についての解説です。 イチイチ署名してませんが, DDBJ のホームページコンテンツには私が書いた文書が多数あります。
上記は書式を時代に合わせる, という1例でしたが, 今度は, 配列決定法の変遷の話題。 EST 受付開始まで行きますと, 少々昔に過ぎて, 私も知らない時代ですが, 当時としては大きな拡張であったろうと思います。 ただ, この時点では DDBJ の中では legacy とか traditional と称している従来の枠組を逸脱する拡張ではありませんでした。 IT 分野の文脈では何故かレガシーに過去の厄介モノの意を含ませる風潮がありますが, 実際の語義は良くも悪くも引き継がれる対象であり, これからも継続すると思います。
この数年で その従来の枠組を逸脱する拡張をしてきました。 2003 年に, ゲノム概要配列の量産の時代に合わせて WGS という枠組を拡張・新設しました。 少し古い記事ですが, WGS のデータ量は新設後, 短期間で飛躍的に増大しました。 2009 年には, いわゆる次世代型とか新世代型などと呼ばれる sequencing platform の普及と配列量産による需要に対応すべく, INSDC に Sequence Read Archive (SRA) が加わりました。 (当時は Short Read Archive と呼ばれていました。) DDBJ も DDBJ Seauence Read Archive (DRA) を新設し対応しています。
時期的には前後しますが, 2003 年から, primary database を逸脱する枠組の拡張が始まりました。 Third Party Annotation (TPA) という別枠で, 配列決定を伴わない配列引用による annotation/assemble/re-assemble の登録を受け付けています。 ただし, データの信頼度を高めるためのハードルとして peer-reviewed な論文公開を伴わないかぎり, データを公開しないという規則の元で運用しています。
生物学, 生命情報科学のコミュニティからの要請・需要の変化に応えるべく, 規則を変化させたり, 枠組を新設したり, いろいろな変化がありましたし, これからも変化することでしょう。 データベースには, システム・ストレージのインフラも大事なのですが, 仕様・枠組に関しても熟考が必要です。 特に, このような「継ぎ足し」のような拡張は通常の保守以上に厄介な局面も多いのです。 現在の課題は, 主に生物多様性研究と個人ゲノム研究の進行に伴うサンプルデータの記述とデータ連携 と感じていますが, それは別の機会に論じてみたいと思います。 ひょっとしたら, この後の回でこの点について何か書く人がいるかもしれません。
4. 登録者とデータベースと利用者を繋ぐ DDBJ の現場
もちろん変わらない基本方針はありますが, 上述のように, 運用と規則は拡張されたり細かい変更を経て現在に至ります。もちろん, 今後も何らかの変化は不断に起こることでしょう。 ルールの変更は登録・更新の現場で annotator の業務自体の変更にあたります。 皆, それぞれに柔軟に時に厳密に対応していることと思います。 多分, この文章を書いている人物の優しい (鬼のような?) 指導の賜物でしょうか?
今後のリレー連載への繋ぎの文章として, 次回以降は, 実際の現場で何が起こっているか, を中心に展開していくことと思います。 多分, 私ではない人が これから書くことですので, 内容は推定です。
1) 欠点はあると思いますが, とにかく利用してくれている研究者は多い SAKURA からの登録がどのように扱われているか? 2) EST, WGS, 全ゲノム規模 などの登録を扱うMass Submission System からの登録受付の実情, 3) それら全てのデータを登録受付後に更新・維持管理をする update 担当 が処理する種々の修正依頼, 4) 配列決定の手法も多様化しつつあり, データ量も増え, 立ち上げから対応に追われている DDBJ Seauence Read Archive (DRA) に関する事情などが予定されています。
また, 機会があれば, annotator とシステム仕様策定とか, 新システム検討の関係について述べることがあるかもしれません。 予定していませんが, 私が再登場する回があるかもしれません。 でも, それはないことを密かに願っています。