Japanese Genotype-phenotype Archive
利用手順
利用申請から JGA データ利用までの手順
利用申請は申請システム に DDBJ アカウントでログインしてから申請します。
利用申請では、利用申請グループの作成、利用希望の JGA Study と Dataset アクセッション番号の指定、及び、「データセット復号用公開鍵」の登録が必要です。
利用申請の承認後、DDBJ アカウントで sftp で JGA サーバにアクセスし、機関内・外サーバへ JGA データをダウンロードすることができます。暗号化されたファイルと復号ツールが提供されるので、申請時に登録した「データセット復号用公開鍵」とペアになる秘密鍵を使って暗号化ファイルを復号してから利用します。
- JGA データセットの検索
- DDBJ アカウントの作成とデータ転送用公開鍵の登録
- 利用申請毎に必要なデータセット復号用公開鍵・秘密鍵ペアの作成
- 利用申請
- データセット復号用公開鍵の登録
- ダウンロード
- データファイルの復号
JGA データセットの検索
利用を希望する Study (例 JGAS999992) と Dataset アクセッション番号 (例 JGAD999993) を確認します。
DBCLS の利用可能な研究データ一覧もしくはDDBJ Search で検索することができます。
DDBJ アカウントの作成とデータ転送用公開鍵の登録
利用申請およびJGA データ取得のためには DDBJ アカウントが必要です。アカウントが無い場合は申請前に DDBJ アカウントを取得してください。
DDBJ アカウント作成後、データ申請システムで利用できるようになるまで10分程度の時間がかかります。
sftp を利用して JGA サーバからデータをダウンロードするためには、データ転送用の公開鍵・秘密鍵ペアを作成し、公開鍵を DDBJ アカウントに登録します。
利用申請毎に必要なデータセット復号用公開鍵・秘密鍵ペアの作成
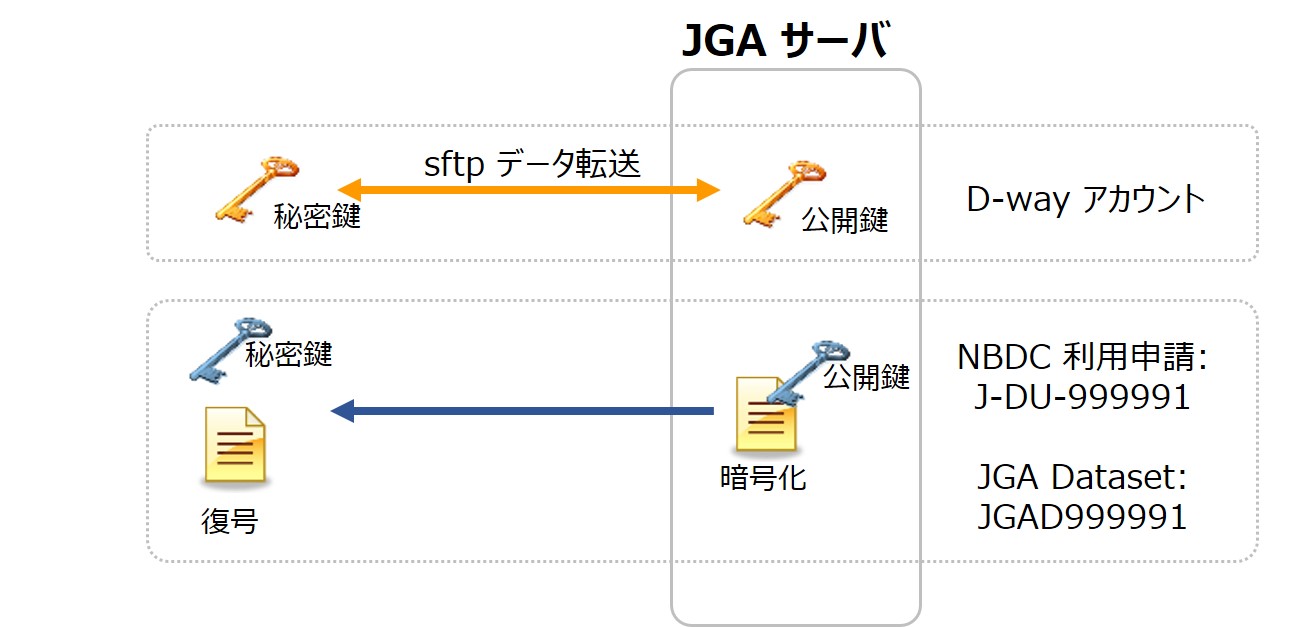
JGA データは暗号化された状態で提供されます。ユーザは利用承認されたデータを sftp でダウンロードし、利用申請時に登録したデータセット復号用公開鍵とペアとなる秘密鍵を使ってデータを復号します。
データセット復号用公開鍵は DDBJ アカウントのデータ転送用公開鍵とは別になります。作成手順は公開鍵/秘密鍵ペアの生成をご覧ください。復号用鍵は RSA 形式で作成する必要があります。ed25519 形式には対応していないのでご注意ください。
利用申請から JGA データ利用までに、データ転送用と復号用に合計2ペア4ファイルの公開鍵・秘密鍵が必要になります。
データセット復号用鍵ペア
- データセット復号用公開鍵 (利用申請毎に登録)
- データセット復号用秘密鍵
データ転送用鍵ペア
- データ転送用公開鍵 (DDBJ アカウントに登録)
- データ転送用秘密鍵
復号用公開鍵と秘密鍵は利用申請 ID をファイル名に含めて保存するとペアを識別しやすくなります。 例
- 復号用公開鍵 J-DU999991.pub
- 復号用秘密鍵 J-DU999991
利用申請
申請システムから利用申請します。
詳細な手順はデータ利用ページをご覧ください。
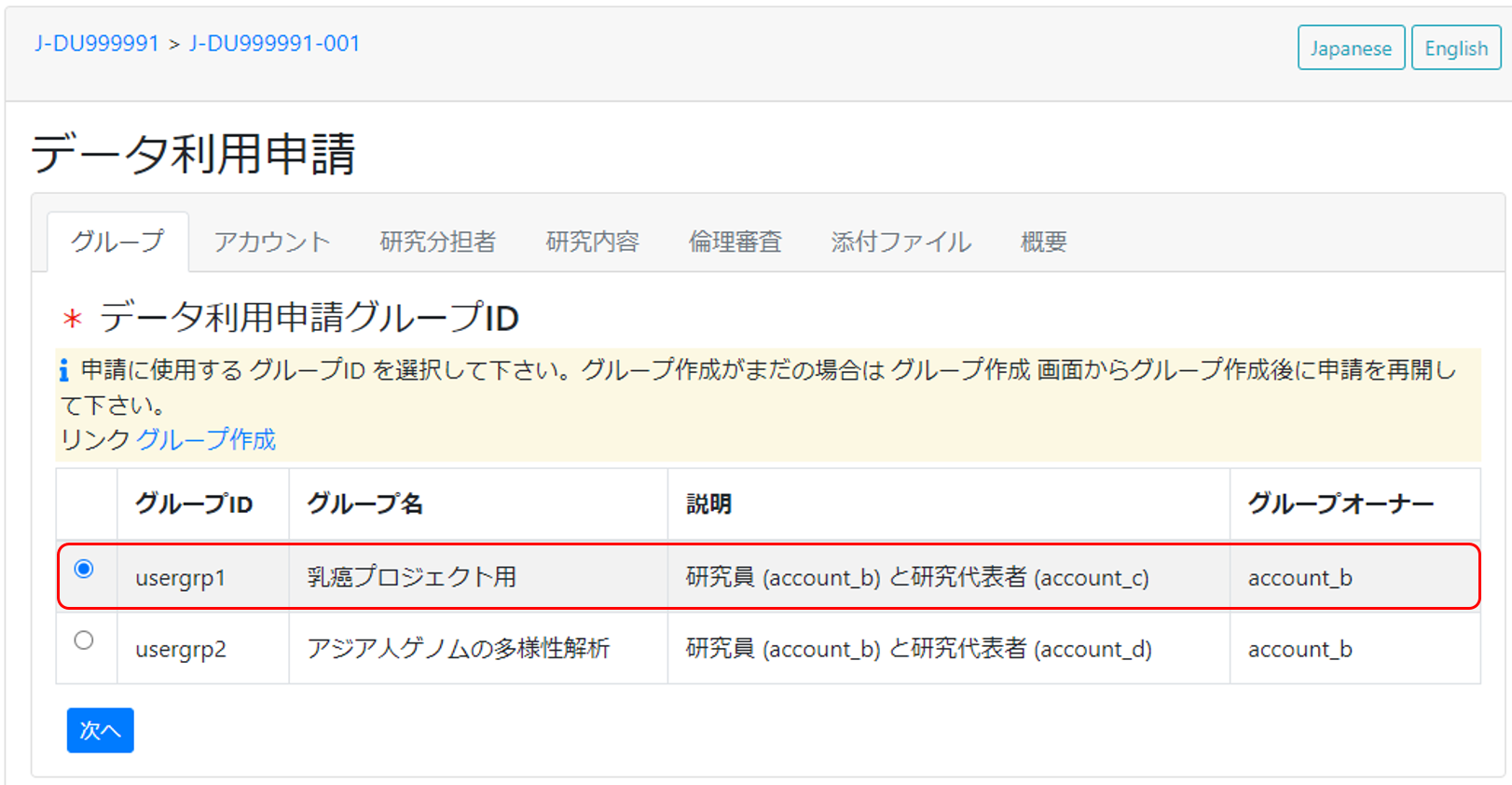
利用申請グループ
申請前に利用申請グループを作成します。例の利用申請グループ (usergrp1)では申請及びダウンロードを担当する研究員 (account_b) がオーナー、研究代表者 (account_c) がメンバーとなっています。

利用申請を開始し、作成した利用申請グループを選択します。
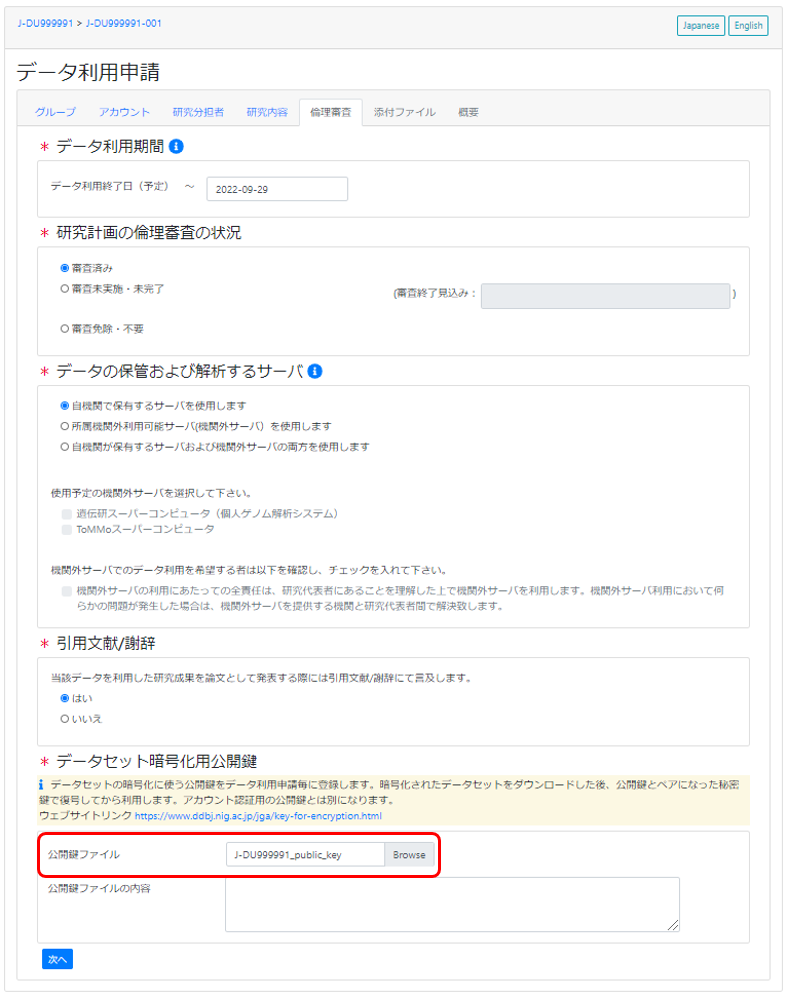
データセット復号用公開鍵の登録
利用申請において「データセット復号用公開鍵」を登録します。
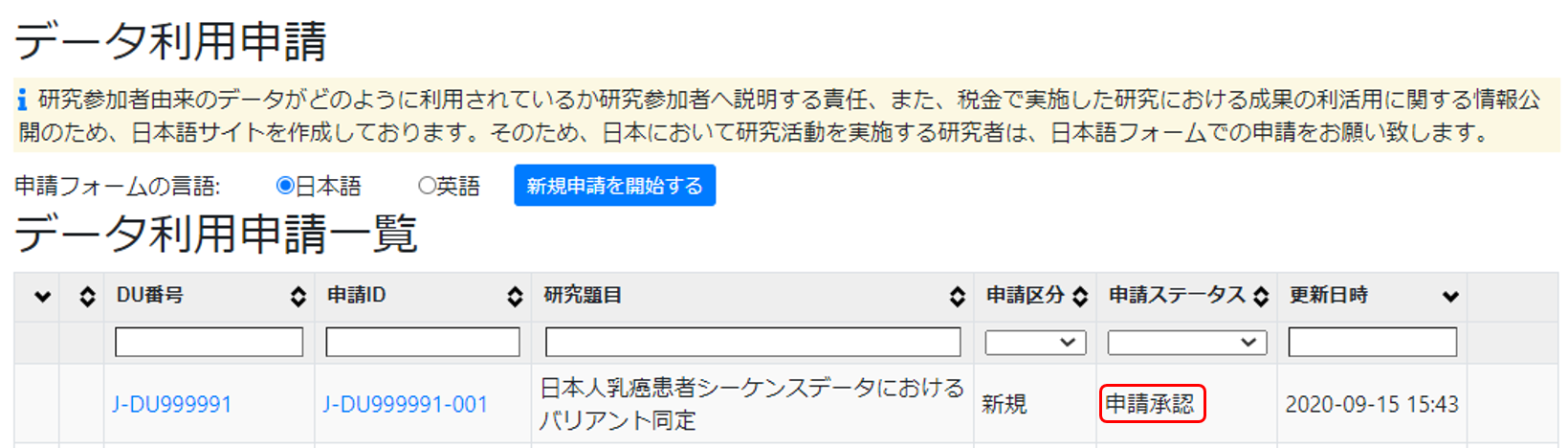
利用承認
利用申請が DBCLS で承認されると、JGA ファイルサーバにダウンロード用ディレクトリが作成され、メタデータ、暗号化されたデータファイルと復号ツールが配置されます。
ダウンロード
sftp を利用して JGA サーバ (jga-gw.ddbj.nig.ac.jp) からデータをダウンロードするためには、データ転送用の公開鍵・秘密鍵ペアを作成し、公開鍵を DDBJ アカウントに登録します。
JGA ファイルサーバ上の /controlled-access/download/jga/ の下にデータ利用申請 DU 番号と同名のディレクトリが作成されます。
WinSCP、もしくは、sftp コマンドを使ってダウンロードします。
WinSCP によるダウンロード
WinSCP (https://winscp.net/eng/download.php) をダウンロードし、Windows PC にインストールします。
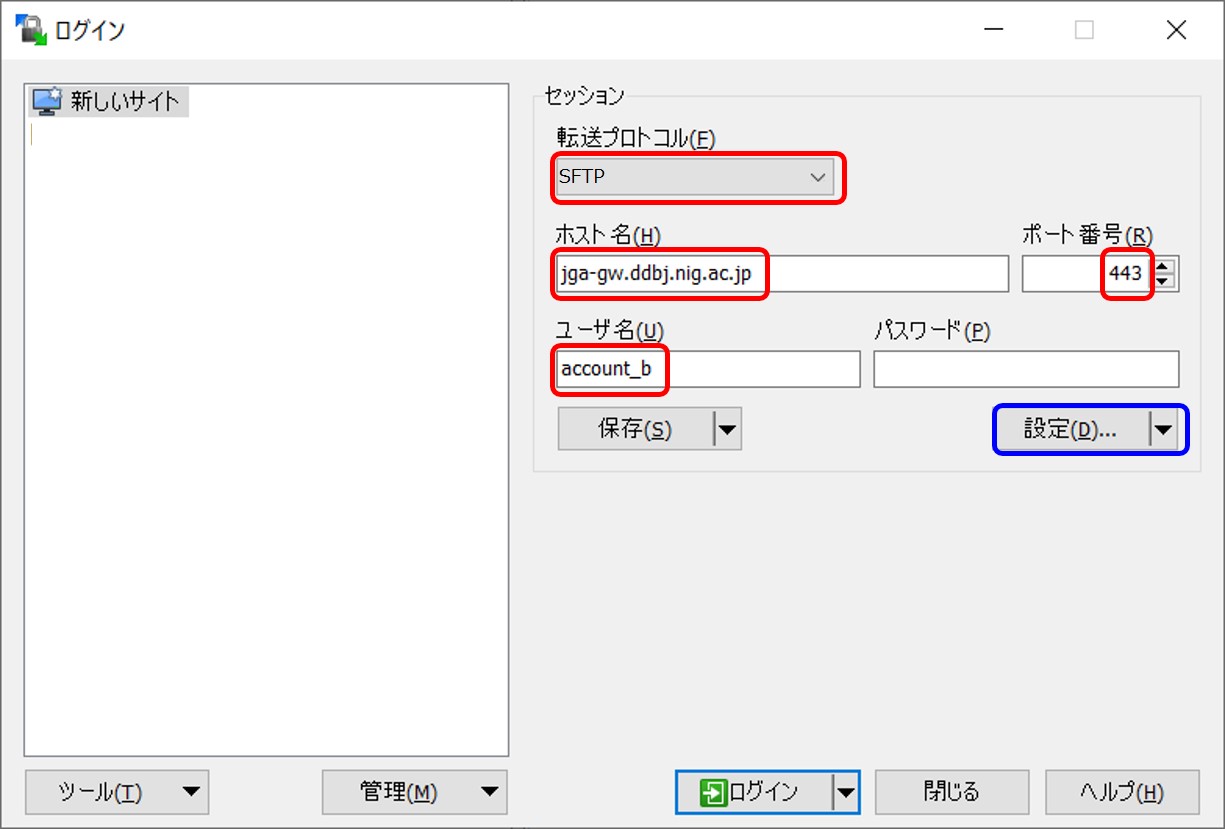
以下のように設定します。
- 転送プロトコル: SFTP
- ホスト名: jga-gw.ddbj.nig.ac.jp
- ポート番号: 443
- ユーザ名: DDBJ アカウント ID
- パスワード: 空欄のまま
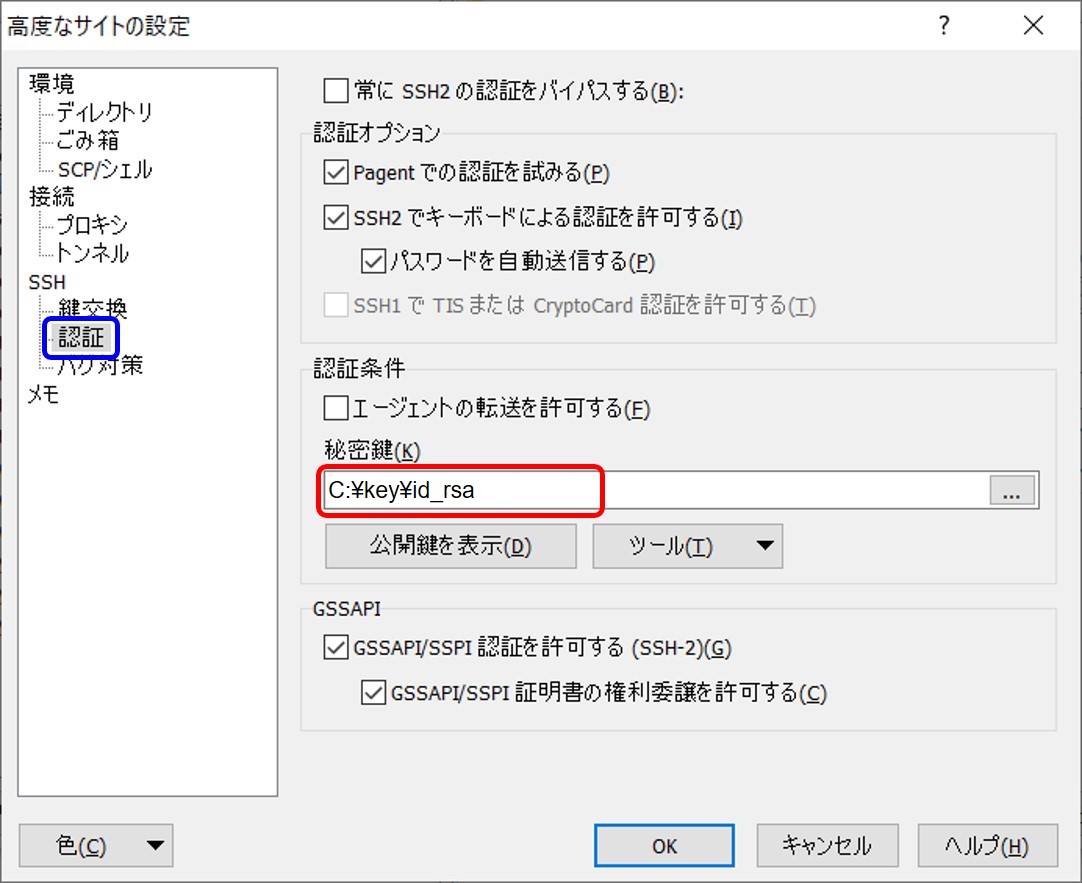
初回接続時には警告メッセージが表示されますが、「はい」を選択してください (次回から表示されません)。次の画面では、鍵を作成した際に指定したパスフレーズを入力します。
ログインに成功すると、左側のウィンドウにユーザの PC のフォルダ、右側のウィンドウに JGA サーバの登録者専用ディレクトリが表示されるので、右側ウィンドウで DU 番号ディレクトリを選択し左側ウィンドウへドラッグ&ドロップし、PC へファイルをダウンロードします。
sftp ダウンロード
sftp の P オプションでポート番号 443 とデータ転送用秘密鍵(データセット復号用公開鍵・秘密鍵とは別になります)を指定してログインし、ディレクトリごとダウンロードします。
# アカウント名: account_b
# 利用申請番号: J-DU999991
# データ転送用秘密鍵のファイルパス: ~/.ssh/id_rsa
$ sftp -i ~/.ssh/id_rsa -P 443 account_b@jga-gw.ddbj.nig.ac.jp
$ cd controlled-access/download/jga/
$ get -r J-DU999991
ダウンロードしたディレクトリの構造
ダウンロードした DU 番号ディレクトリ直下には Study ディレクトリ、及び、データファイルの復号ツールが配置された tools ディレクトリがあります。Study ディレクトリの下に Dataset ディレクトリがあり、Dataset ディレクトリの下にタブ区切りテキスト(tsv)ファイルと XML 形式のメタデータを含む metadata ディレクトリ、及び、暗号化されたデータファイルを含む Data と Analysis ディレクトリがあります。
以下の番号とデータファイルを例としてデータの利用方法を説明します。
# JGA Study: JGAS999992
# JGA Dataset: JGAD999993
# JGA Data: JGAR999999994-JGAR999999995
# JGA Analysis: JGAZ999999996-JGAZ999999997
$ tree J-DU999991/
J-DU999991/
├── JGAS999992 # JGA Study
│ └── JGAD999993 # JGA Dataset
│ ├── JGAR999999994 # JGA Data
│ │ └── case1.fastq.gz.encrypt # 暗号化ファイル
│ ├── JGAR999999995 # JGA Data
│ │ └── case2.fastq.gz.encrypt # 暗号化ファイル
│ ├── JGAZ999999996 # JGA Analysis
│ │ └── case1.vcf.gz.encrypt # 暗号化ファイル
│ ├── JGAZ999999997 # JGA Analysis
│ │ └── case2.vcf.gz.encrypt # 暗号化ファイル
│ └── metadata
└── tools
└── J-DU999991.tool.zip
データファイルの復号
復号ツールは Linux で実行してください。Windows はサポートしていません。
ダウンロードした暗号化ファイルは、復号ツールを使って復号します。利用者の解析環境で J-DU999991 ディレクトリ直下に移動し、tools ディレクトリにある復号ツール「J-DU999991.tool.zip」を、(tools ディレクトリの下ではなく)J-DU999991 ディレクトリ直下に展開します。復号処理スクリプトおよび暗号化済み共通鍵ファイルが展開されます。DU 全体を対象とする復号スクリプト J-DU999991.decrypt.sh が、J-DU999991 ディレクトリ直下に、個々のデータファイルを対象とする case1.fastq.gz.decrypt.sh のような復号スクリプトが暗号化されたデータファイルが含まれる Data/Analysis ディレクトリに配置されます。
$ cd J-DU999991
$ unzip tools/J-DU999991.tool.zip
$ tree ../J-DU999991/
J-DU999991/
├── J-DU999991.decrypt.sh # DU 単位の復号処理スクリプト
├── JGAS999992
│ └── JGAD999993
│ ├── JGAR999999994
│ │ ├── case1.fastq.gz.decrypt.sh # ファイル毎の復号処理スクリプト
│ │ ├── case1.fastq.gz.encrypt
│ │ └── case1.fastq.gz.encrypt.dat # 共通鍵ファイル
│ ├── JGAR999999995
│ │ ├── case2.fastq.gz.decrypt.sh # ファイル毎の復号処理スクリプト
│ │ ├── case2.fastq.gz.encrypt
│ │ └── case2.fastq.gz.encrypt.dat # 共通鍵ファイル
│ ├── JGAZ999999996
│ │ ├── case1.vcf.gz.decrypt.sh # ファイル毎の復号処理スクリプト
│ │ ├── case1.vcf.gz.encrypt
│ │ └── case1.vcf.gz.encrypt.dat # 共通鍵ファイル
│ ├── JGAZ999999997
│ │ ├── case2.vcf.gz.decrypt.sh # ファイル毎の復号処理スクリプト
│ │ ├── case2.vcf.gz.encrypt
│ │ └── case2.vcf.gz.encrypt.dat # 共通鍵ファイル
│ └── metadata
└── tools
└── J-DU999991.tool.zip
# .decrypt.sh: 復号処理スクリプト
# .dat: 暗号化済み共通鍵ファイル
全ての復号処理スクリプトに対して実行権限を付与します。
以下のようにワイルドカード (*) を使ったコマンドを実行するとデータファイル毎の復号処理スクリプトに対して一括で実行権限を付与することができます。
$ chmod 750 J-DU999991.decrypt.sh
$ chmod 750 */*/*/*decrypt.sh
利用申請時に登録したデータセット復号用公開鍵とペアになっている「秘密鍵」を指定して「J-DU999991.decrypt.sh」を実行し、全データファイルを復号します。
- -k: データセット復号用公開鍵とペアの秘密鍵を指定 (例:J-DU999991_private_key)
- -p: 秘密鍵のパスフレーズ (以下で ****** となっている部分) を指定(パスフレーズを指定していない場合は省略)
$ ./J-DU999991.decrypt.sh -k J-DU999991_private_key -p ******
$ ls JGAS999992/JGAD999993/JGAR999999994/
case1.fastq.gz # 復号されたデータファイル
case1.fastq.gz.decrypt.sh
case1.fastq.gz.encrypt
case1.fastq.gz.encrypt.dat
$ ls JGAS999992/JGAD999993/JGAZ999999996/
case1.vcf.gz # 復号されたデータファイル
case1.vcf.gz.decrypt.sh
case1.vcf.gz.encrypt
case1.vcf.gz.encrypt.dat
DU ディレクトリ下にある Study や Dataset ディレクトリを sftp した場合、以下のようなディレクトリ配置にしてから復号スクリプトを実行します。
DU ディレクトリ直下に DU 単位の復号スクリプトと暗号化されたデータファイルが含まれている Study/Dataset/Data もしくは Analysis ディレクトリを配置します。
$ J-DU999991/
J-DU999991/J-DU999991.decrypt.sh
J-DU999991/JGAS999992/JGAD999993
復号処理の並列化
復号処理を同時にバックグラウンド実行することで並列化することができます。
状況にも依りますが、マルチコア CPU を使っており計算資源に余裕がある場合は高速化することができます。
「データファイルのあるディレクトリに移動し、ファイル毎の復号シェルをバックグラウンド実行する」シェルスクリプトを作成し、実行します。
ファイルの配置はダウンロード時点から変更されていないことが前提になります。
#! /bin/sh
cd JGAS999992/JGAD999993/JGAR999999994/
./case1.fastq.gz.decrypt.sh -k J-DU999991_private_key -p ****** &
cd ../../../JGAS999992/JGAD999993/JGAR999999995/
./case2.fastq.gz.decrypt.sh -k J-DU999991_private_key -p ****** &
cd ../../../JGAS999992/JGAD999993/JGAR999999996
./case1.vcf.gz.decrypt.sh -k J-DU999991_private_key -p ****** &
cd ../../../JGAS999992/JGAD999993/JGAR999999997
./case2.vcf.gz.decrypt.sh -k J-DU999991_private_key -p ****** &
メタデータ
metadata ディレクトリには以下のファイルが含まれています。メタデータファイルは暗号化されていません。
メタデータ tsv ファイルの例
メタデータオブジェクトの内容が記述された tsv ファイル
- JGAD999993.sample.txt
- JGAD999993.analysis.SEQUENCE_VARIATION.txt
メタデータを見やすくするため、Sample 及び Analysis については、1行目に項目名、2行目以降に内容が記述された tsv ファイルが提供されます。Analysis の tsv ファイル名には Analysis type(種類)が含まれており、type 毎に作成されます。なお Study、Dataset、Policy はオープンなメタデータとして DDBJ Search でも内容を見ることができます。
メタデータオブジェクトの対応関係と内容を記述した tsv ファイル
- JGAD999993.study_sample_experiment_data.mapping.txt
Data → Experiment → Sample → Study の対応関係を示した表。Experiment と Data についてはこの対応表がオブジェクトの内容表示を兼ねています。
- JGAD999993.study_analysis_sample.mapping.txt
Analysis → Sample → Study の対応関係を示した表。複数サンプルの結果をまとめた解析データなど、Analysis が複数 Sample を参照している場合はアクセッション番号ではなく参照している Sample の「数」が記載されます。
- JGAD999993.analysis_sample.mapping.txt
Analysis と Sample の対応表。Analysis が複数 Sample を参照している場合、全ての Sample アクセッション番号が列挙されます。
- JGAD999993.dataset_policy_data_analysis.mapping.txt
Dataset に含まれる Data、Analysis とリンクしている Policy の対応表。
各オブジェクトのメタデータ XML ファイル
- JGAD999993.study.xml
- JGAD999993.dataset.xml
- JGAD999993.policy.xml
- JGAD999993.sample.xml
- JGAD999993.experiment.xml
- JGAD999993.data.xml
- JGAD999993.analysis.xml
- JGAD999993.dac.xml
プログラムで機械処理する場合などに利用できます。
ファイルリスト
- JGAD999993.filelist.txt
データファイルの名前、種類、サイズ、復号前後の MD5 ハッシュ値、及び、含まれている Data と Analysis アクセッション番号をまとめた表。 手許でダウンロードしたファイルの MD5 ハッシュ値を取得し、リスト中の値と比較することでファイルの破損チェックを行うことができます。
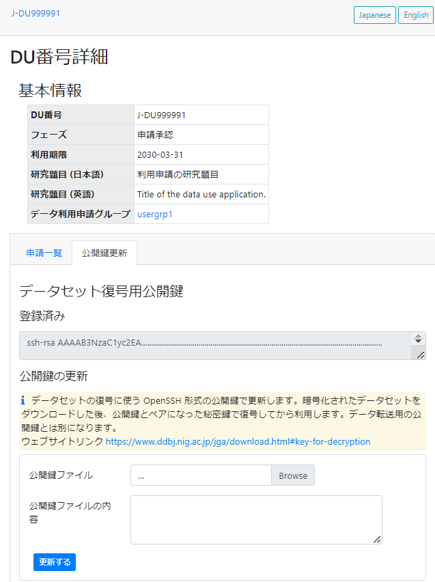
データセット復号用公開鍵の更新
利用申請の「公開鍵更新」から鍵の更新ページに移動します。
OpenSSH 形式の新しい公開鍵を選択し、「更新する」をクリックしてデータセット復号用の公開鍵を更新します。
利用対象データセットの再処理が開始されますので、処理が完了するまで鍵の更新をしないようにします。
利用するデータファイル数が数千を超えるような場合、データセットの再処理に数日間かかります。
再処理が完了するまで公開鍵の更新は実施しないでください。
再処理が完了したかどうかは復号用ツール(例 J-DU999991.tool.zip)の timestamp が前回から更新されているかどうかで判断することができます。
再処理完了後、ダウンロードの手順に従い、復号用ツールのみを再度ダウンロードします。データファイルは再度ダウンロードする必要はありません。
データファイルの復号の手順に従い、データファイルを新しく更新した公開鍵とペアになっている秘密鍵を指定して復号します。