DDBJ Annotated/Assembled Sequences
Haplotype
これまで全ゲノムシークエンスでは相同染色体のアリルを区別せず、コンセンサス配列として結果を得ることが一般的でした。しかし、ロングリード・シークエンス技術によりハプロイドを区別してシークエンスすることが可能になりました。Haplotype シークエンスは同じサンプルから二つのゲノムデータが得られるという特徴があるため、INSDC ではデータの登録方法を定めています。DDBJ ではこのような配列に対して pseudohaplotype という用語を使用していましたが、haplotype に変更しました。
Haplotype の登録
DDBJ に Haplotype アセンブリを登録する典型的な場合について説明します。Haplotype を区別する方法はいくつかありますが、ここでは片方を Principal とし、もう片方を Alternate と呼ぶことにします。各 Haplotype は同じサンプルに由来するため、共通の BioSample を使います。INSDC では BioProject と BioSample の組み合わせでアセンブリを管理しているため、組み合わせが Haplotype 毎にユニークになるように Principal と Alternate に対応する BioProject をそれぞれ作成します。さらにアンブレラ BioProject を作成し、両方の BioProject をまとめます。
Haplotype をシークエンスした生データを DRA に登録する場合、両方の Haplotype 由来のリードが混在している場合、BioProject はアセンブリとは別に DRA 用のものを登録します。BioSample はサンプルがアセンブリと同じであれば、共通のものを使います。
Haplotype のデータセットが複数存在する場合 (例 生物種 A, B, C の Haplotype 3セット)、各セット用の BioProject を作成し、共通のアンブレラ BioProject でまとめます。
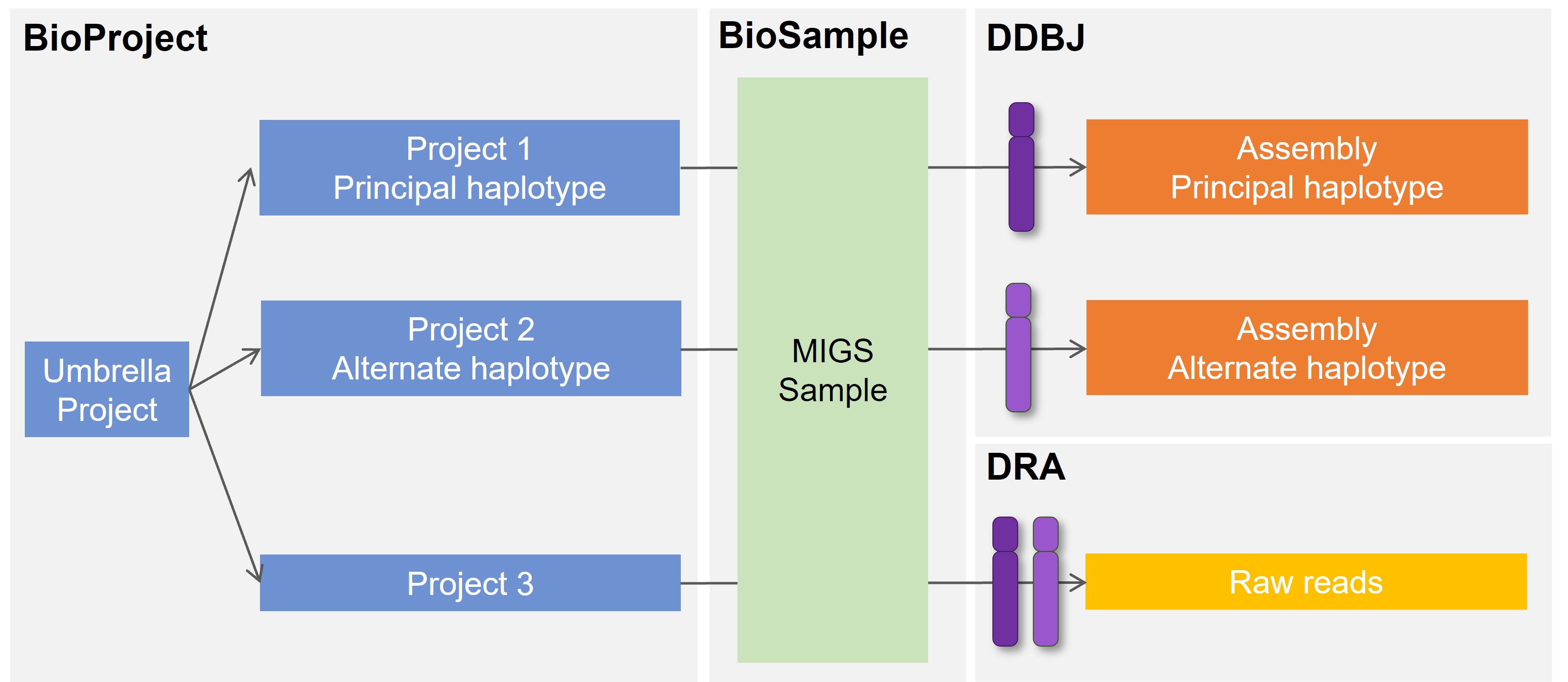
Haplotype アセンブリを区別する名称
Haplotype アセンブリを区別するための名称については、以下のいずれかから登録者が判断します。
- Principal haplotype/Alternate haplotype: どちらかの品質がもう一方よりも優れている場合、優れている方を Principal、もう片方を Alternate とします。
- Haplotype 1/Haplotype 2: 品質が同等の場合。二つ以上の haplotype が存在する場合、Haplotype 3/Haplotype 4 のように数字を増やします。
- Maternal haplotype/Paternal haplotype: 由来親が分かっている場合。
BioProject
Principal と Alternate haplotype に対応するプロジェクトをそれぞれ登録し、両者をまとめるアンブレラプロジェクトを登録します。アンブレラプロジェクトを登録する際、Private comments to DDBJ staff に配下にリンクする primary BioProject のアクセッション番号とその区別を記入します (例 PRJDB1 Principal, PRJDB2 Alternate, PRJDB3 DRA)。
- BioProject 1: Principal
- title に haplotype のフェーズに関する情報を記載。例 Principal haplotype や Primary haplotype
- BioProject 2: Alternate
- title に haplotype のフェーズに関する情報を記載。例 Alternate haplotype や Alternate haplotype
- Umbrella BioProject
- BioProject 1, 2 と他の関連する BioProject(図の例では DRA 用の BioProject 3)をまとめる。
BioSample
サンプルは haplotype で共通であるため、一つのゲノム用サンプルを登録します。
- パッケージはゲノム用の MIGS を選択。
- Principal と alternate haplotype が由来する共通サンプルを一つ登録。
- Haplotype に遺伝子アノテーションを付与する場合、Principal と Alternate で使う共通の locus tag prefix を locus_tag_prefix 属性に記入します。プレフィックスが共通でもタグで Haplotype を区別することができます。例 A1C_p00001 (Principal) と A1C_a00001 (Alternate)
DDBJ
Principal と Alternate haplotype をそれぞれ登録します。
- Principal haplotype
- DBLINK で BioProject 1 (Principal) を参照します。
- ST_COMMENT に所定のコメントを記載します。Genome-Assembly-Data ST_COMMENT: Diploid :: Principal haplotype
- Alternate haplotype
- DBLINK で BioProject 2 (Alternate) を参照します。
- ST_COMMENT に所定のコメントを記載します。Genome-Assembly-Data ST_COMMENT: Diploid :: Alternate haplotype
登録例
共通
- BioProject: PRJDB10054 (Umbrella)
- BioSample: SAMD00229903
Principal haplotype
- BioProject: PRJDB10055
- DDBJ: BLYA01000001-BLYA01003780
Alternate Haplotype
- BioProject: PRJDB10056
- DDBJ: BLYB01000001-BLYB01003780
DRA
- BioProject: PRJDB9979
- DRA: DRR231909-DRR231923