DDBJ Annotated/Assembled Sequences
DDBJ 塩基配列登録システム HELP
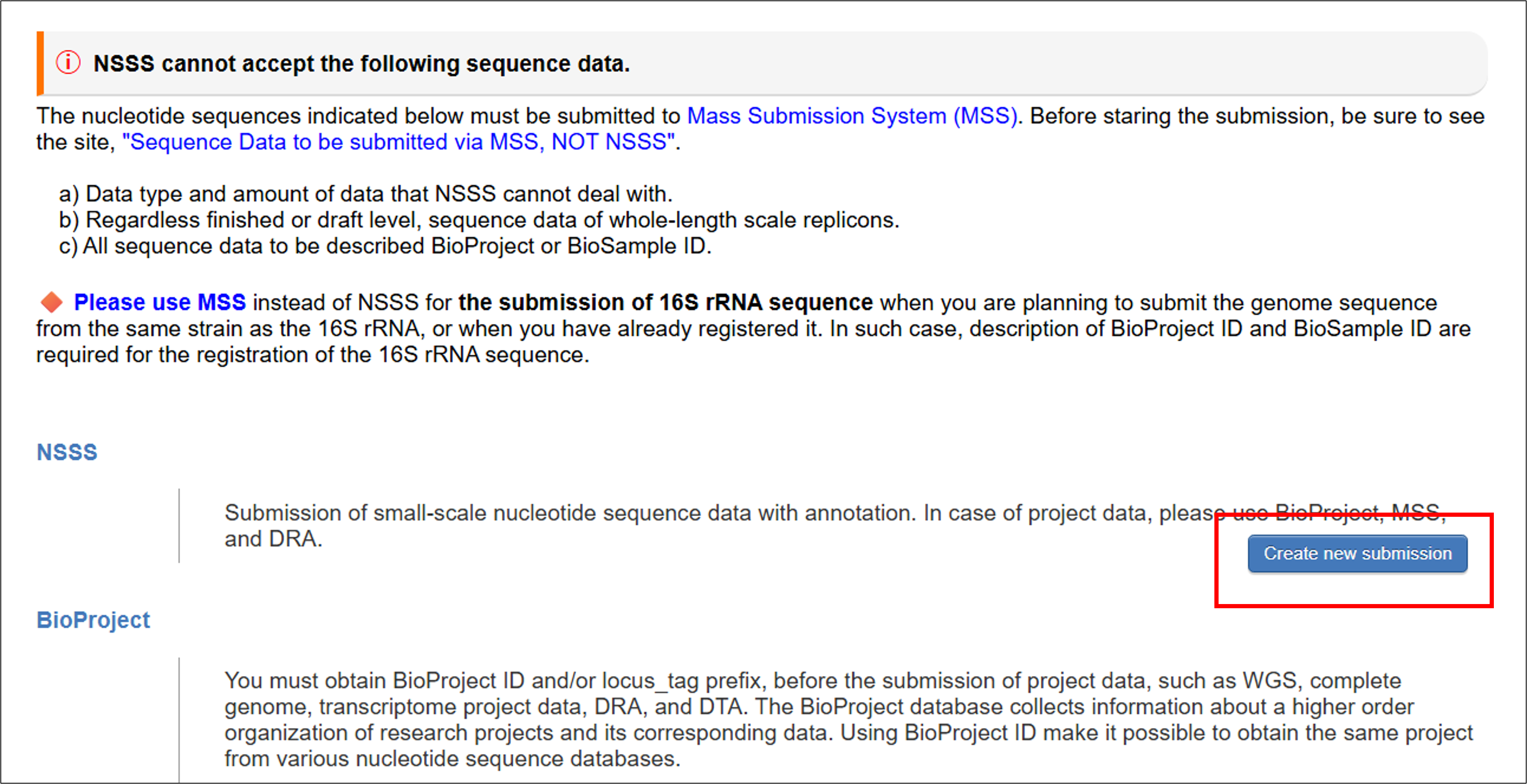
Start
https://ddbj.nig.ac.jp/submission/にアクセスし、Create new submissionボタンをクリックしてsubmissionを開始します。
1. Contact person
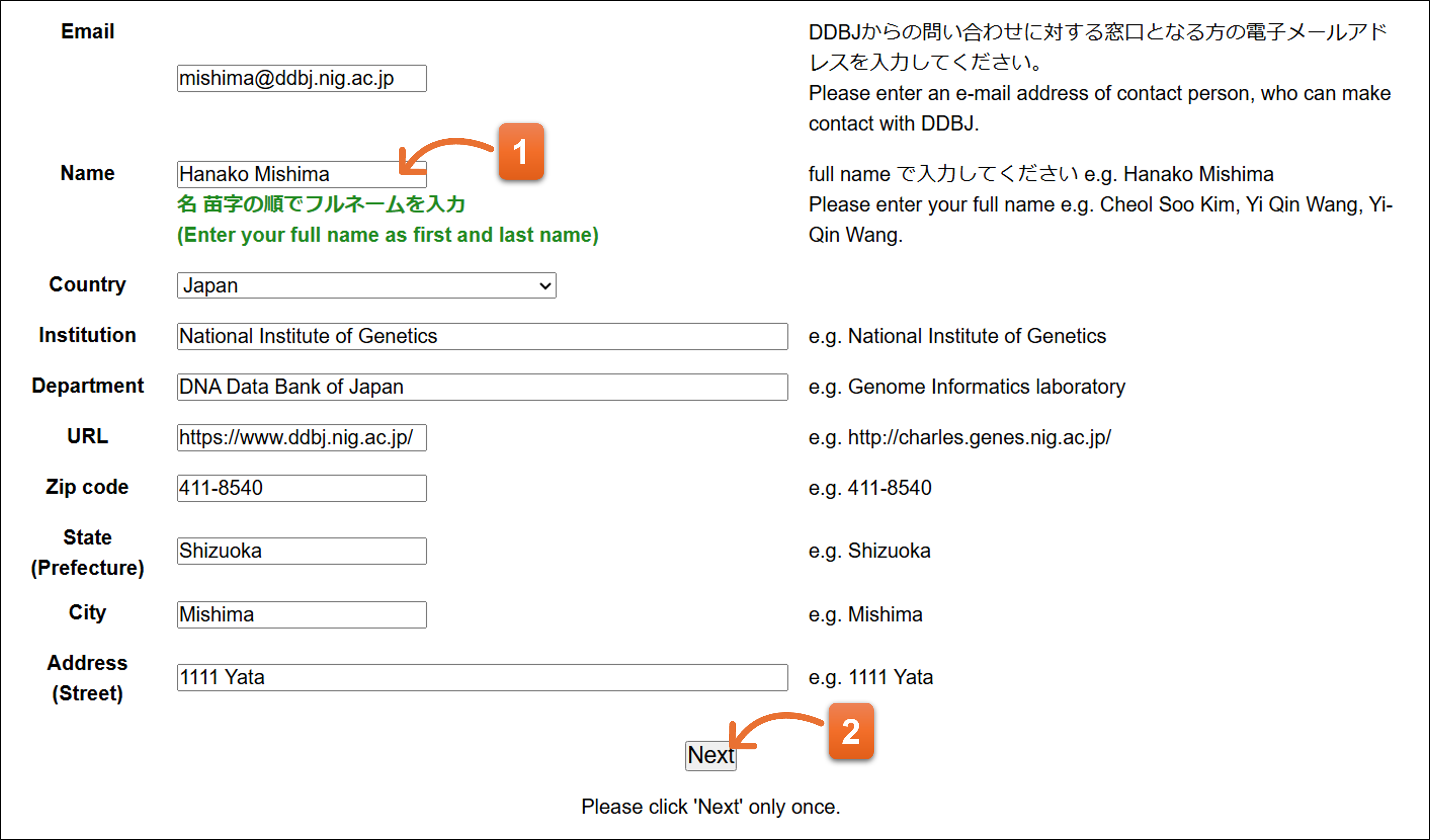
コンタクトパーソン情報を入力します。
- コンタクトパーソンの氏名はFull nameで入力します。
- 入力後”Next”ボタンをクリックします。入力したメールアドレス宛にメールが自動送信されます。
メール本文内のリンクをクリックすればブラウザが開いて、続きを入力できるようになります。または、このURLをコピーしてブラウザのアドレス欄に貼り付け、リターンキーを押します。

2. Hold date
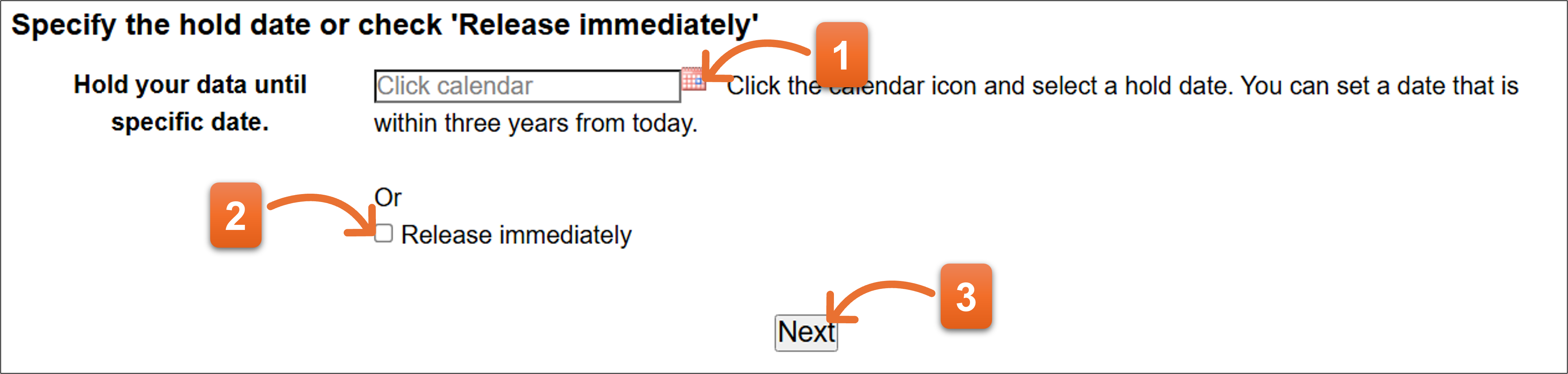
公開日(Hold date) をカレンダーから選択するか、即公開を希望する場合は “Release immediately” チェックを加えます。年末・年始はDDBJが公開作業を停止するため選択できません。選択できる日付は最大3年後までです。
- カレンダーアイコンをクリックし、表示されるカレンダーから公開処理希望日を指定してください。
- 即公開希望の場合は、ここにチェックを加えてください。
- 入力がすんだら”Next”ボタンをクリックします。
入力の中断・再開方法について
- このページ以降、”Next”をクリックしてからブラウザでブックマークすれば、ブラウザを閉じた後でもブックマークしたURLを用いて再開することが可能です。
- “7.Annotation”ページでのアノテーション入力時は、”Next”クリック前であっても入力途中のアノテーションは保持されますので、ブックマークからアノテーション入力を再開することが可能です。
3. Submitter
登録者(Submitter)名を入力します。
- コンタクトパーソンの氏名がsubmitter書式に合うよう自動変換され、表示されます。修正が必要な場合、適宜変更してください。
- 登録者を追加できます。DDBJでは、複数の登録者の指定をお願いしております。公開される塩基配列ファイルには、ここで入力した順序通りに名前が表示されます。
- 入力後”Next”をクリックします。
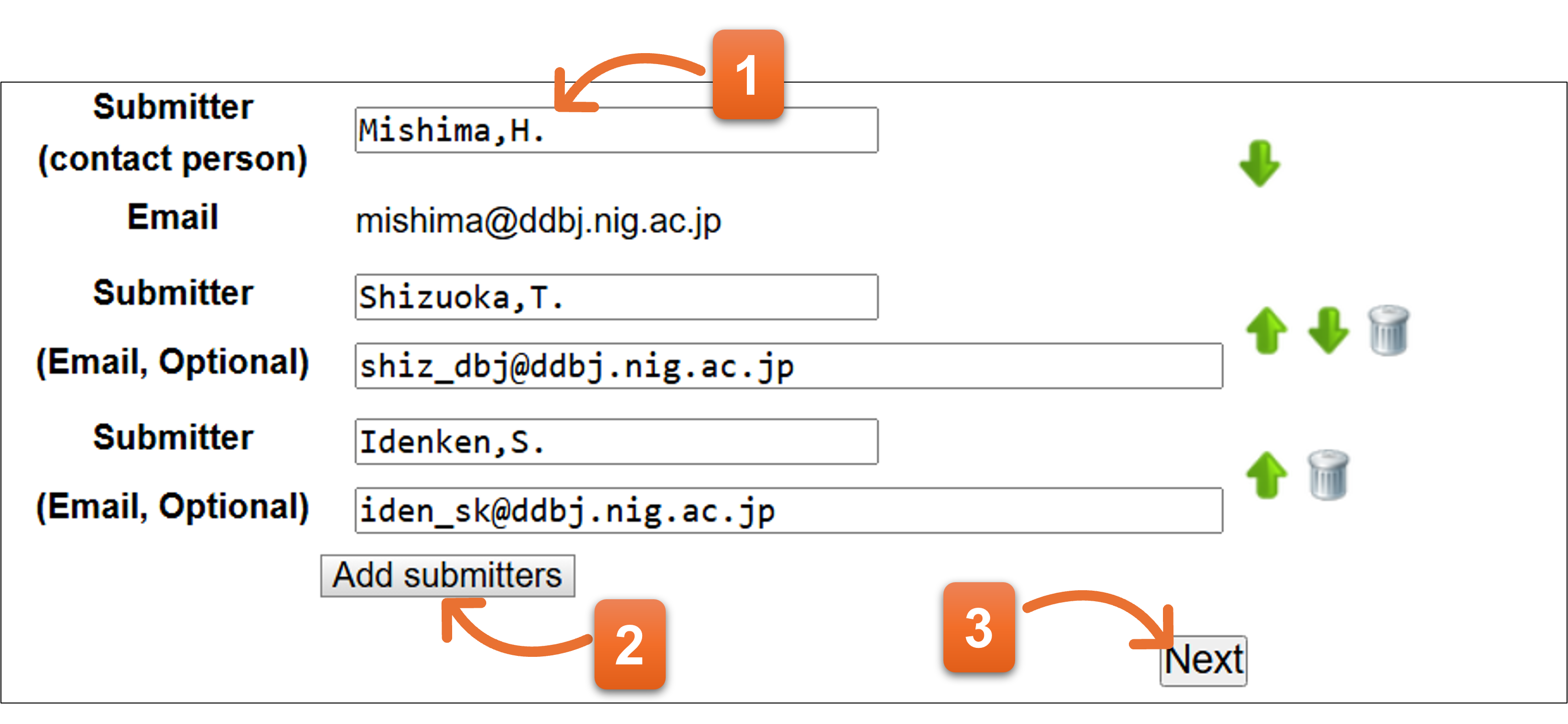
Submitter には、例のように氏名の略記を記載してください。
書式: Last name[comma]Initial of first name[period]Initial of middle name[period]
例
Miyashita,Y.
Robertson,G.R.
Mishima-Tokai,H.
Kim,C.S.
Wang,Y.Q.
- 登録者は複数名を指定いただけるよう、お願いしております。
登録者が1名のみの場合、将来、修正が必要になった際に私どもから登録者本人への連絡がとれない場面に遭遇することもございます。1名の登録者のみでの登録も可能ですが、複数の登録者を記載いただけるよう推奨しております。たとえば、実作業者と研究指導者(責任者)、論文著者から登録者に加えるなど、2名以上の登録者記載に関しましてご協力をお願いいたします。
関連するページ
DDBJ のデータ公開形式 (flat file) の説明, REFERENCE 1
4. Reference
論文(Reference)情報を入力します。配列に関する主論文(Primary citation)を第一referenceに入力してください。
- デフォルトでUnpublishedが選択されています。Unpublishedは、以下の場合に選択します。
– 論文準備中、または論文投稿中、または論文を作成する予定がない場合
論文が受理されているときは In pressを、論文がすでに公開されているならPublishedを選択してください。Unpublished、In press、Publishedの選択に応じてフォームの入力欄が切り替わります。 - Referenceを追加する場合にクリックします。
書式: Last name[comma]Initial of first name[period]Initial of middle name[period]
例
Miyashita,Y.
Robertson,G.R.
Mishima-Tokai,H.
Kim,C.S.
Wang,Y.Q.
関連するページ
REFERENCE 2
各Statusでの入力例
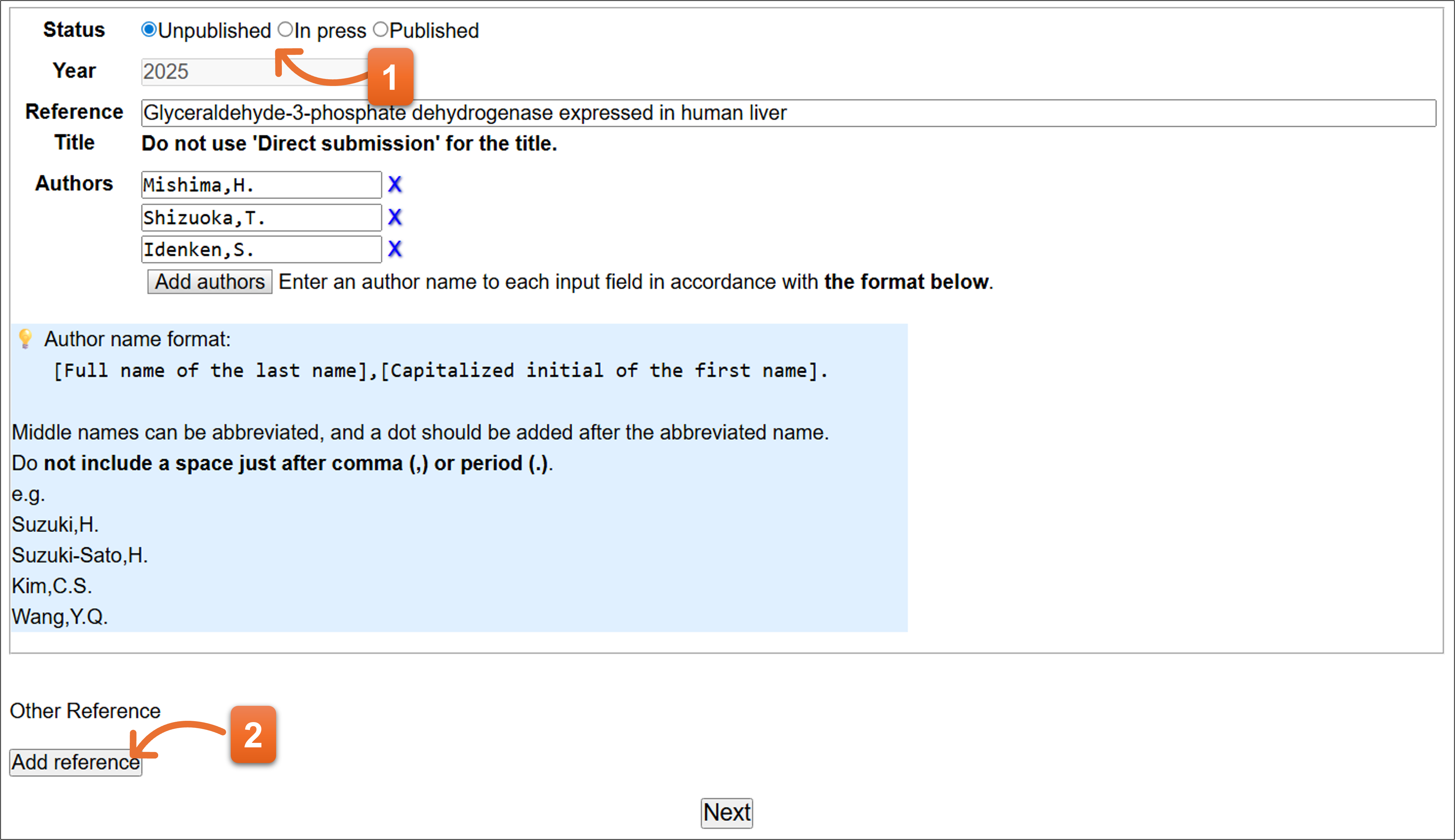
Status: Unpublished
- 自動で今年の年が入力済みになります。
- 論文タイトルを入力します。論文を準備しない場合でも、塩基配列に応じた適切なタイトルをつけて記載してください。
- 論文の著者名を各欄に1名ずつ入力してください。Add authorsボタンで入力欄を追加できます。Xをクリックすると、入力欄を消去できます。
- 入力後クリックします。
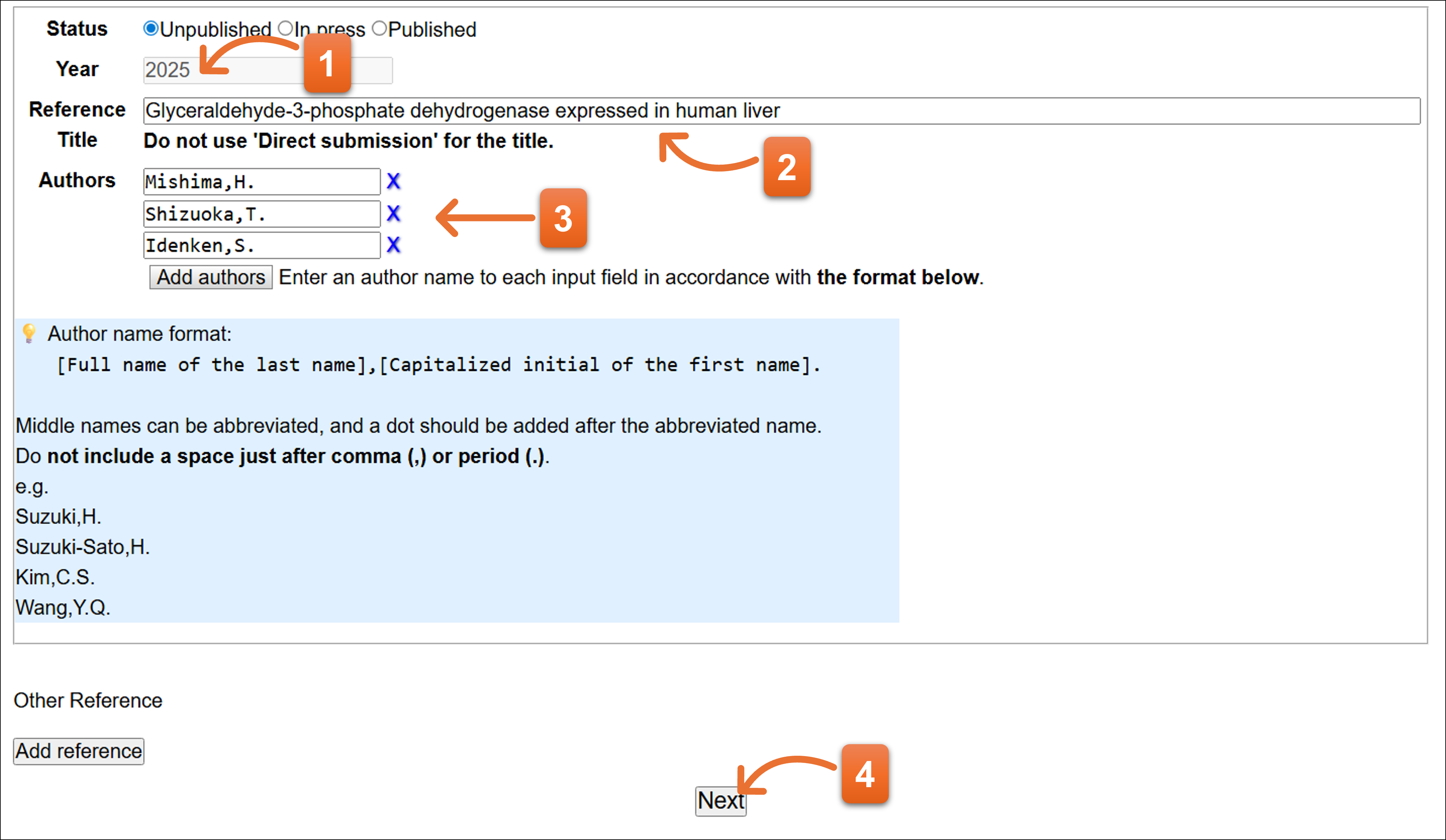
Status: In press
- Yearを入力します。
- In press選択時、Journalの略称名で入力してください。ここの入力欄では、Journal略称入力のための補完機能を利用できます。
- 論文タイトルを入力します。
- 論文の著者名を各欄に1名ずつ入力してください。Add authorsボタンで入力欄を追加できます。Xをクリックすると、入力欄を消去できます。
- 入力後クリックします。
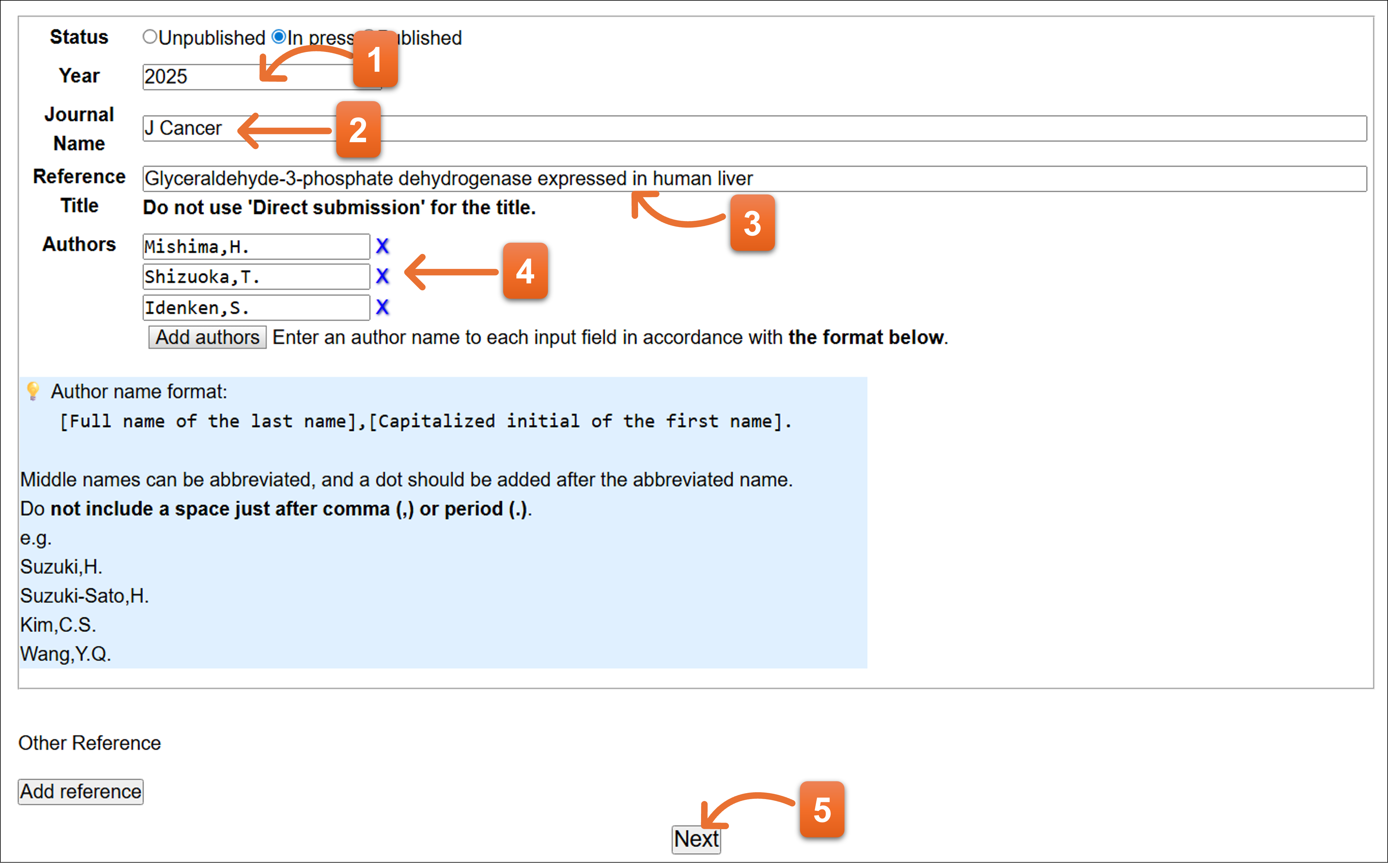
Status: Published
- Yearを入力します。
- Published選択時、Journalの略称名で入力してください。ここの入力欄では、Journal略称入力のための補完機能を利用できます。
- 論文タイトルを入力します。
- Volume、pageを入力します。DOIがわかる場合は入力してください。
- 論文の著者名を各欄に1名ずつ入力してください。Add authorsボタンで入力欄を追加できます。Xをクリックすると、入力欄を消去できます。
- 入力後クリックします。
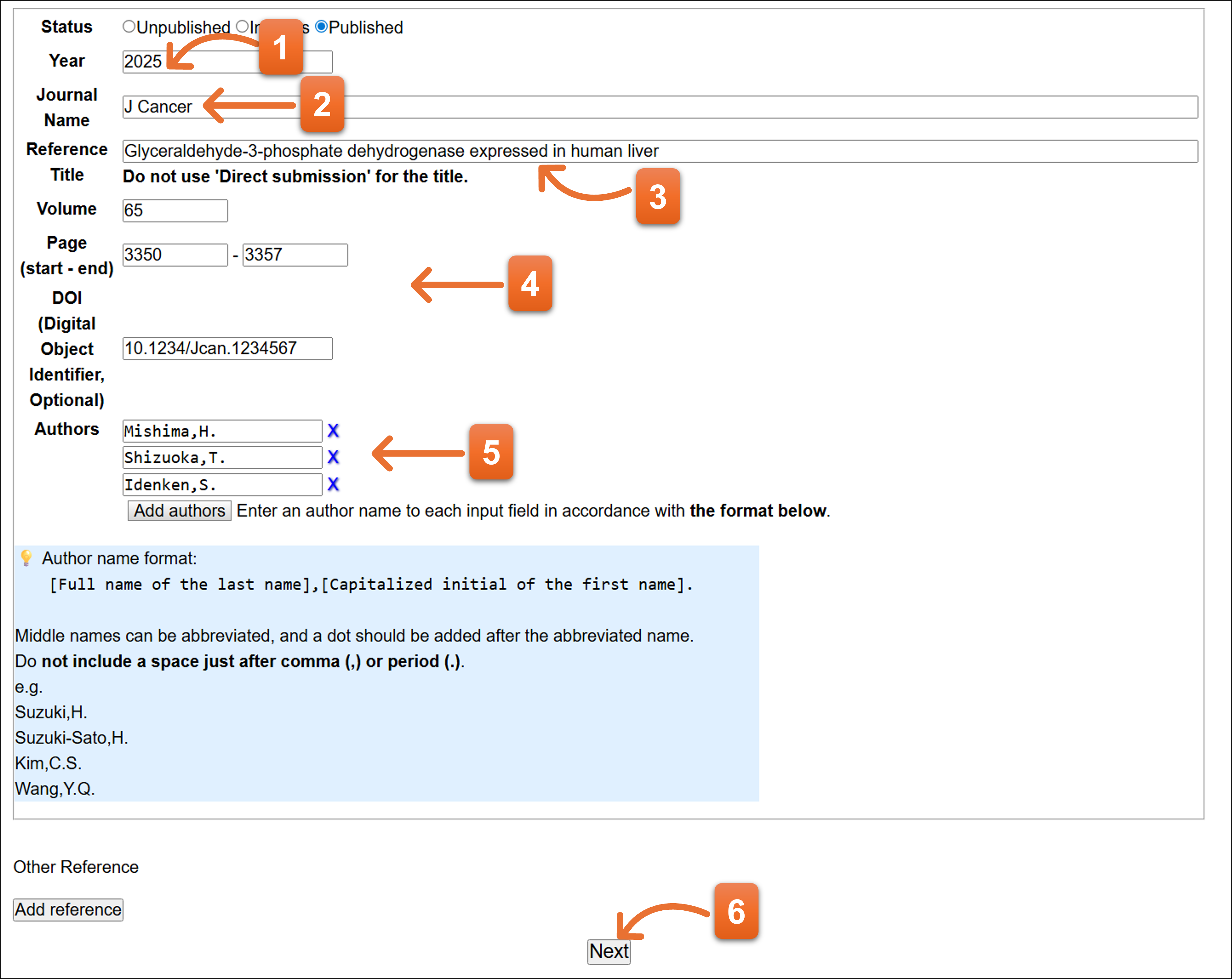
Journal name
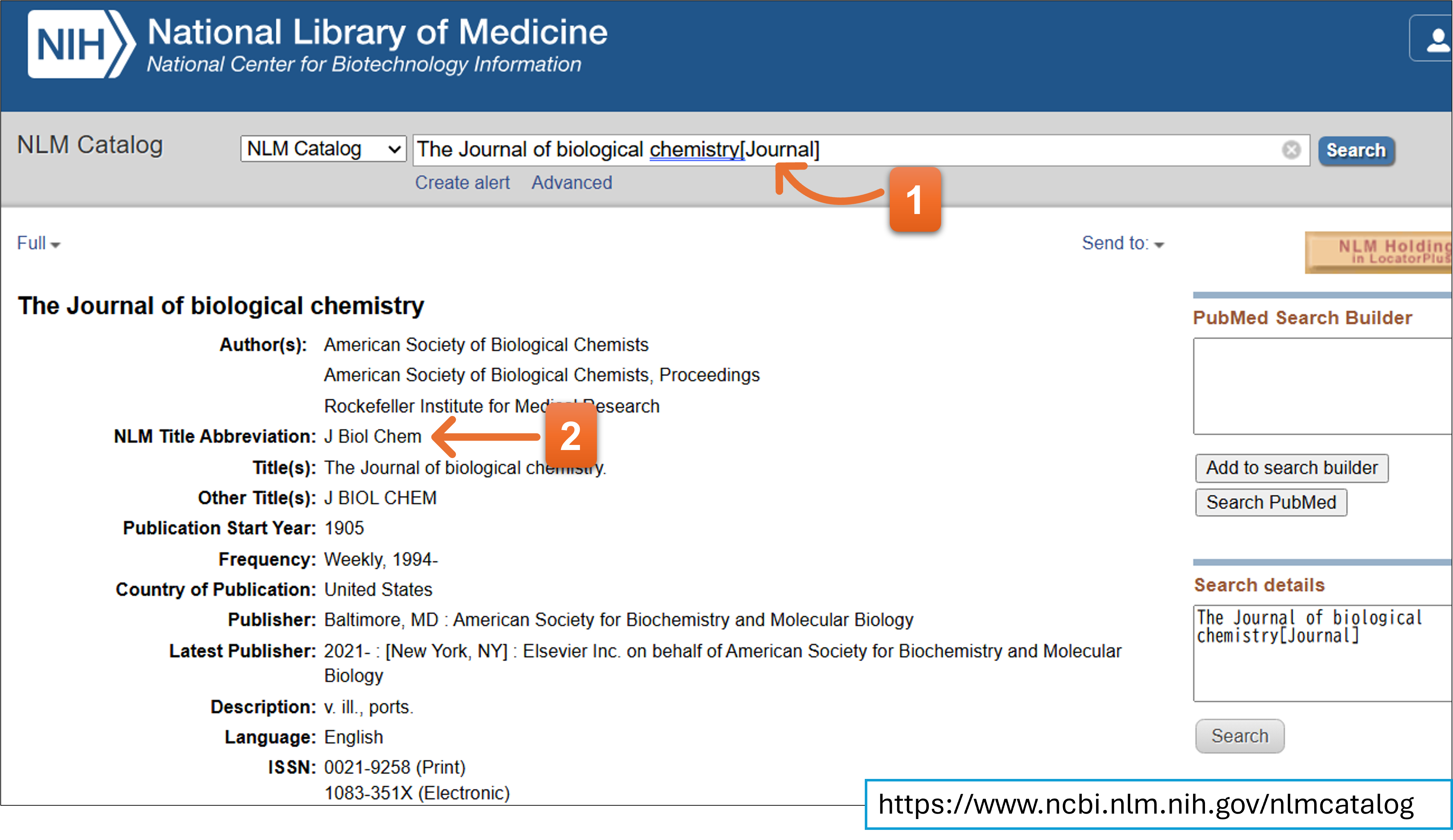
Journal nameをabbreviationで入力してください。Journalのfull nameを入力していくと候補が現れますので、マウスで選択することでJournalのabbreviationを入力できます。

JournalのabbreviationはNLM Catalogで調べることができます。
- 調べたいジャーナル名の直後に[Journal]を添えて、検索します。
- Title Abbreviationの欄に表示される名称です。
5. Sequence
塩基配列を入力します。TPAのsubmissionを行うことはできません。TPAはMSSで受け付けます。
- デフォルトで”YES”が選択されています。TPAに該当しない場合、ここの回答はYESのままにします。
- 塩基配列をペースト、または、塩基配列ファイルをアップロードしてください。
- 入力後クリックします。
📌‼ アノテーション入力後、このフォームにおいて塩基配列の内容を変更した場合、”7.Annotation”で入力した内容はすべで失われます。
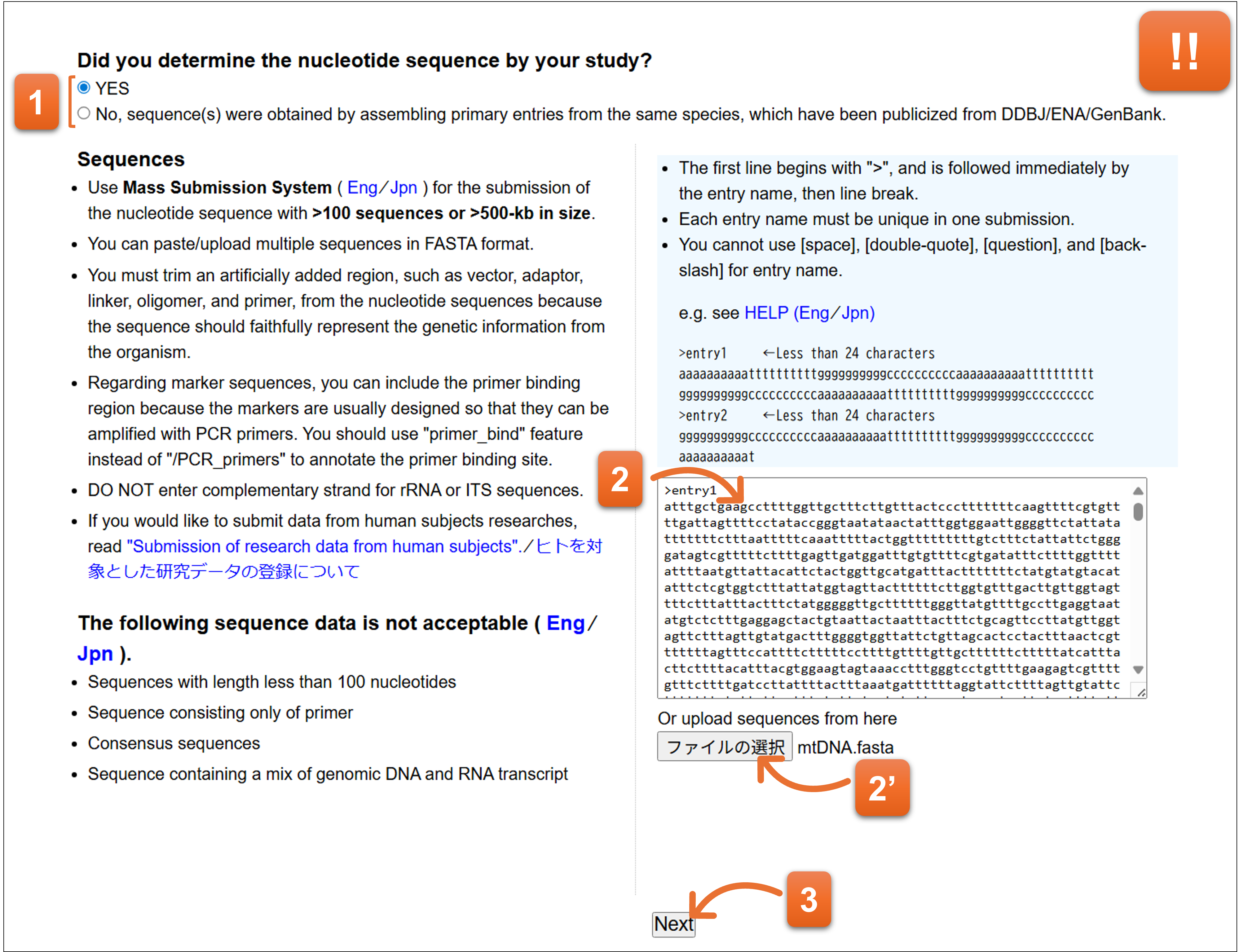
塩基配列のフォーマットについて
-
Multi-FASTA 形式の塩基配列をペースト(またはアップロード)可能です。
-
Entry name (エントリー名) は、24文字までの半角・英数記号(ただしスペース、”[double-quote]、?[question]、¥[yen sign]、\[back-slash]を含まない)を用いて設定してください。
-
Entry name には、それぞれ異なる名称を付けてください。
同じ Entry name が使用されている場合はエラーとなるため Entry name の修正が必要になります。 -
各エントリーの区切りとして // [double slash] を挿入する必要はありませんが、// をエントリーの区切りとして使用しても構いません(例1、例2)。
-
本システムでは // 無しの塩基配列を入力した場合、各エントリーの区切りとして // が自動的に挿入されます。
-
塩基配列は、a, c, g, t, m, r, w, s, y, k, v, h, d, b, n のいずれかで構成される必要があります。
-
塩基配列中の スペース、数字は自動的に削除されます。
-
塩基配列中の大文字は自動的に小文字に変換されます。
例1
>CLN01
ggacaggctgccgcaggagccaggccgggagcaggtggtggaagacagacctgtaggtgg
aagaggcttcgggggagccggagaactgggccagaccccacaggtgcaggctgccctgtc
tgcgcttcagtcgtgggcgaagcctgaggaaaaagagagagaggctcaaggaagagagga
tgaggcaggagaatcgcttgaaccccggaggcggaggttgcagtgagccgagattacgcc
accgcactccagcctgggcgacagagtgagactccatctcaaaaaaaaaaaaaaaaaa
>CLN02
ctcacacagatgctgcgcacaccagtggttgtaacaatgccgtttgcctccttcaggtct
gaagcctgaggtgcgctcgtggtcagtgaagagggcaaaaagagagagaggctcaaagga
tgcgcttcagtcgtgggcgaagcctgaggaaaaagagagagaggctcaaggaagagagga
tagtcattcatataaatttgaacacacctgctgtgcctagacaagtgtctttctgtaaga
gctgtaactctgagatgtgctaaataaaccctctttctcaaaaaaaaaaaaaaaa
例2
>CLN01
ggacaggctgccgcaggagccaggccgggagcaggtggtggaagacagacctgtaggtgg
aagaggcttcgggggagccggagaactgggccagaccccacaggtgcaggctgccctgtc
tgcgcttcagtcgtgggcgaagcctgaggaaaaagagagagaggctcaaggaagagagga
tgaggcaggagaatcgcttgaaccccggaggcggaggttgcagtgagccgagattacgcc
accgcactccagcctgggcgacagagtgagactccatctcaaaaaaaaaaaaaaaaaa
//
>CLN02
ctcacacagatgctgcgcacaccagtggttgtaacaatgccgtttgcctccttcaggtct
gaagcctgaggtgcgctcgtggtcagtgaagagggcaaaaagagagagaggctcaaagga
tgcgcttcagtcgtgggcgaagcctgaggaaaaagagagagaggctcaaggaagagagga
tagtcattcatataaatttgaacacacctgctgtgcctagacaagtgtctttctgtaaga
gctgtaactctgagatgtgctaaataaaccctctttctcaaaaaaaaaaaaaaaa
//
6. Template
アノテーションに適合するtemplateを選択します。
- まず、適切なtaxonomic divisionを選択します。
- つづいてアノテーションテンプレートを選択します。
- リストに該当する項目がない場合、または、アノテーションファイルをアップロードする場合には、otherを選択します。なお、other選択時にはテーブル形式のアノテーション入力を利用できません。
- テンプレート選択後、Input annotation(画面でアノテーションを入力する場合)またはUpload annotation file(アノテーションファイルをアップロードする場合)をクリックします。
📌‼ このページにおいてテンプレート変更を行った場合、”7.Annotation”で入力した内容は失われます。

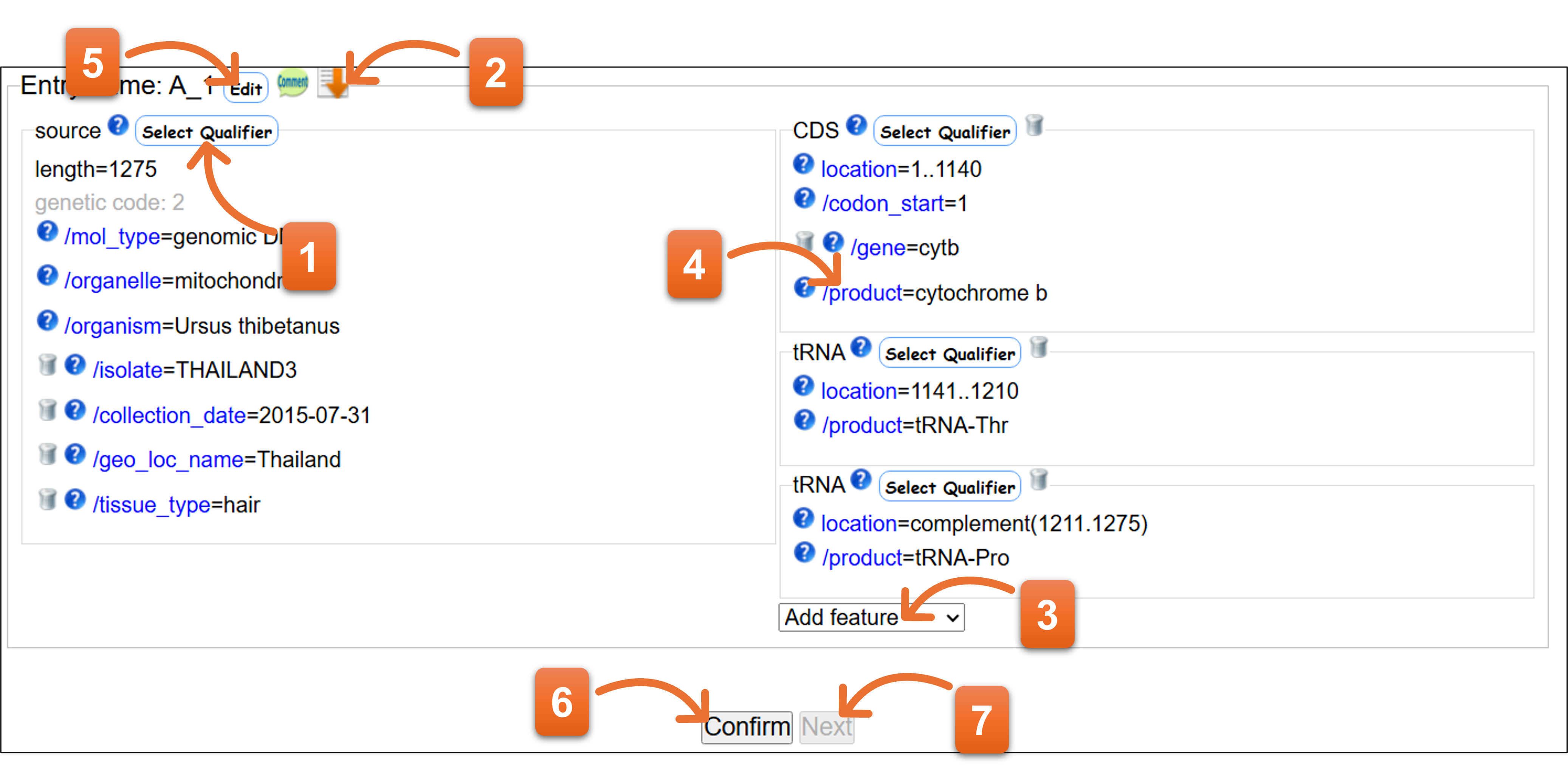
7. Annotation
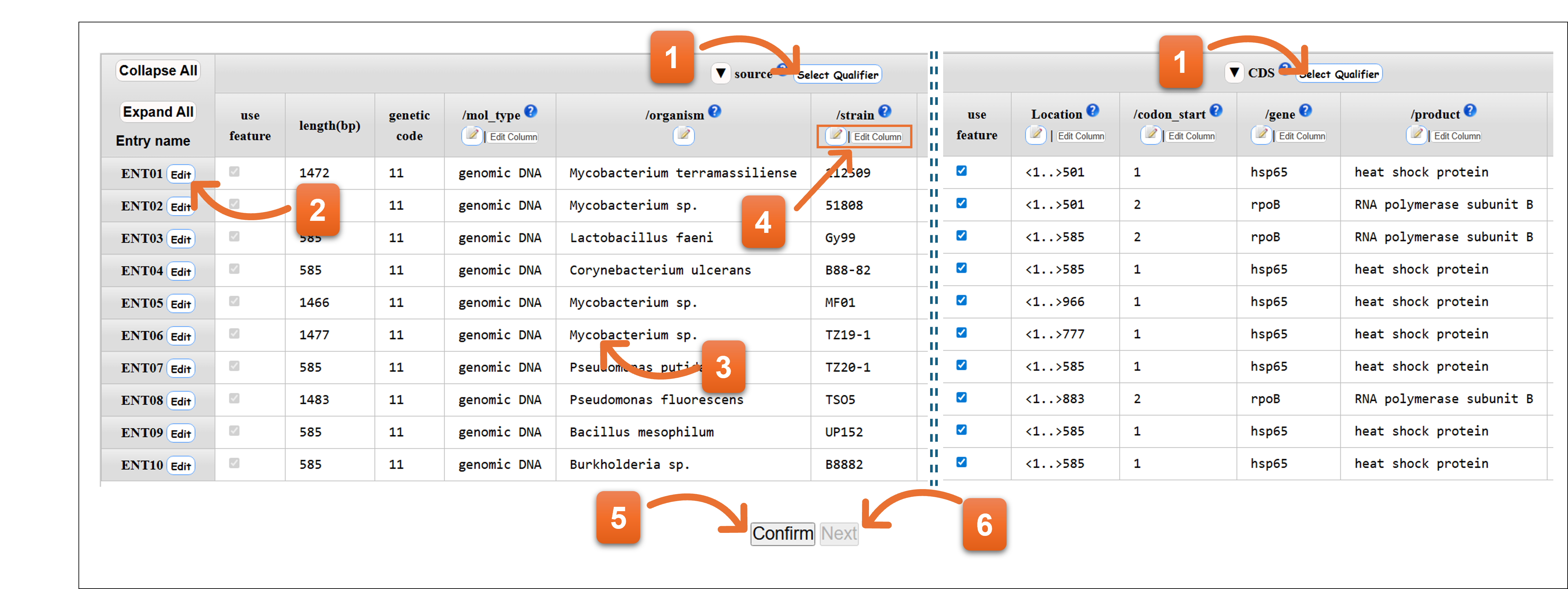
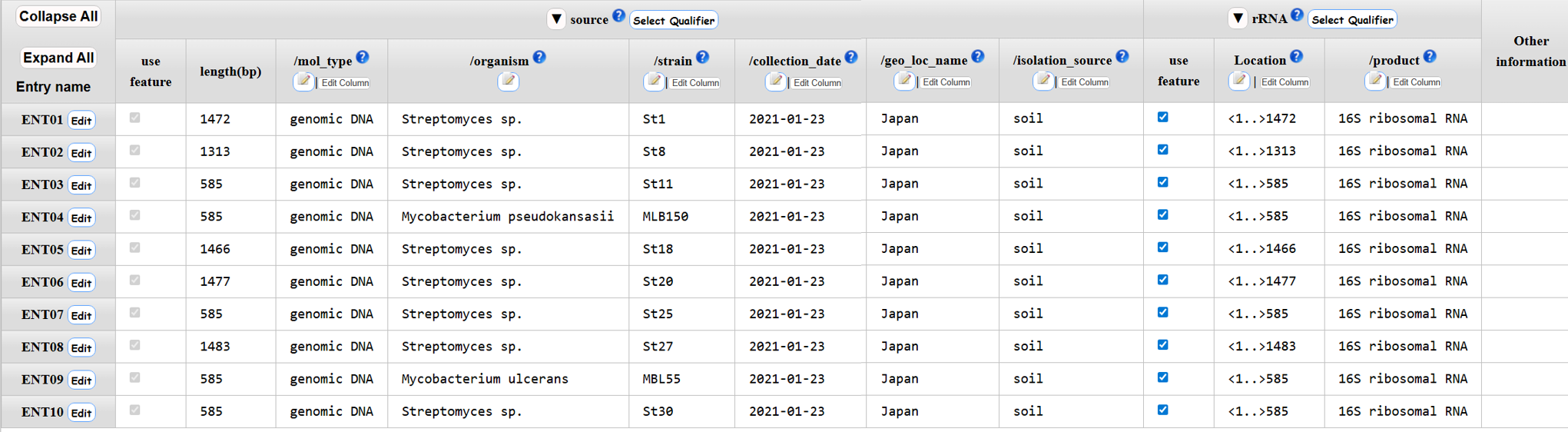
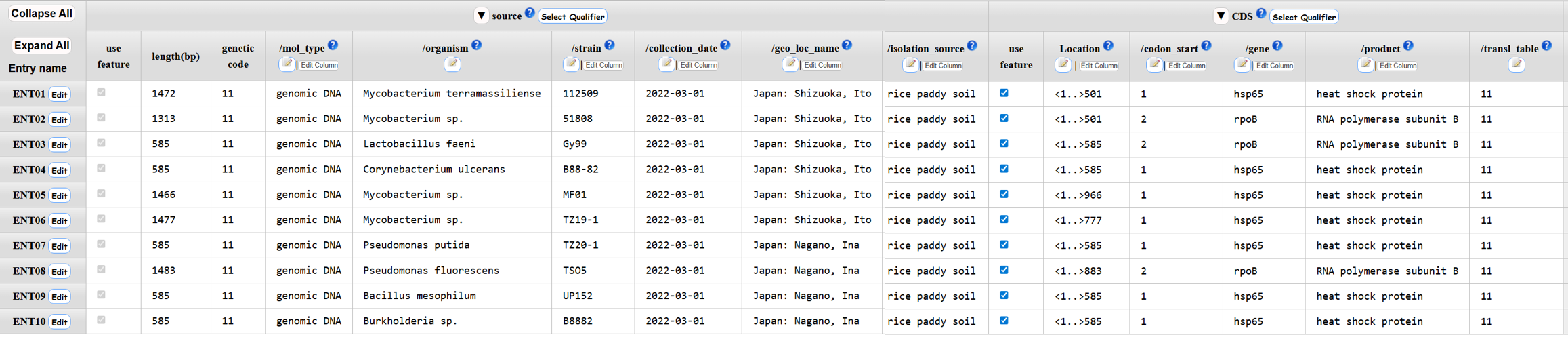
アノテーション画面 - Template で “other” 以外を選択したとき
- qualifierを追加または削除します。
- Editアイコンでは、エントリーごとにアノテーションを入力できます。
- セルをダブルクリックして、セルごとに入力を行えます。
- 縦列の編集が可能です。
- アノテーション入力完了後、アノテーションチェックのためクリックしてください。
- アノテーションチェックの結果エラーがある場合はNextをクリックできません。Confirmでエラーがなくなるまでアノテーションを修正後、Nextをクリックします。
- 関連するページ
- Feature key の定義 / Qualifier key の定義 / Organism qualifier に記載する生物名 / タンパク質コード配列; CDS feature について
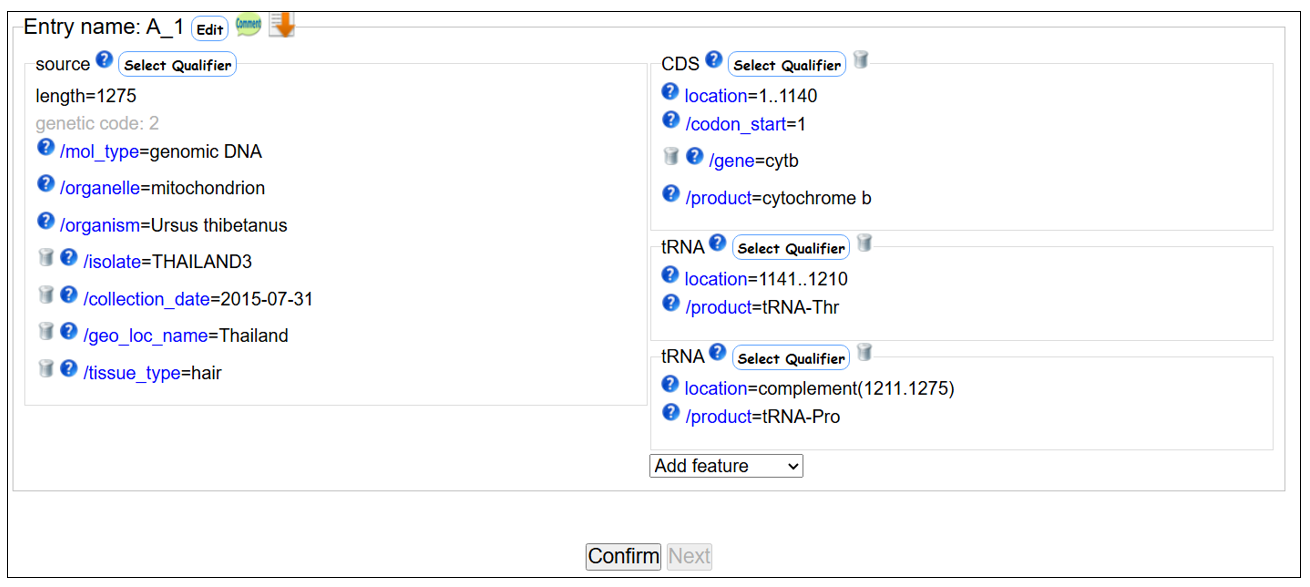
アノテーション画面 - Template で “other” を選択したとき
- Qualifierを追加または削除します。
- sourceフィーチャーに追加したqualifier keyを、この後のすべてのエントリーに追加しておきたい場合にクリックします。
- Featureを追加します。
- LocationやQualifierを直接クリックして入力できます。
- Editアイコンでは、エントリーごとにアノテーションを入力できます。
- アノテーション入力完了後、アノテーションチェックのためクリックしてください。
- アノテーションチェックの結果エラーがある場合はNextをクリックできません。Confirmでエラーがなくなるまでアノテーションを修正後、Nextをクリックします。
- 関連するページ
- Feature key の定義 / Qualifier key の定義 / Organism qualifier に記載する生物名 / タンパク質コード配列; CDS feature について
アノテーションの入力方法
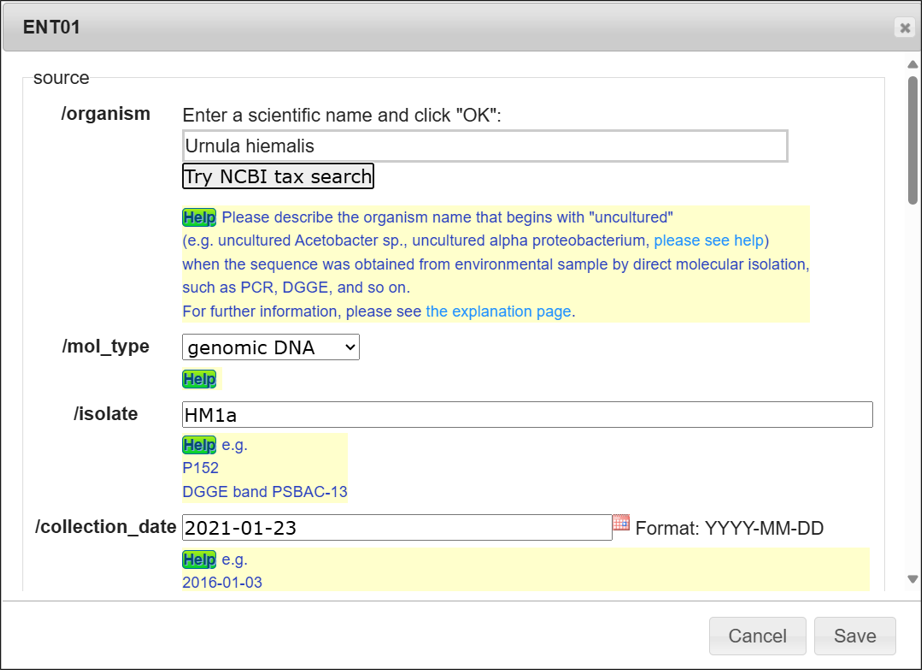
“Edit”ボタン
1エントリーごとのアノテーションを入力できます。アノテーション入力後、Saveボタンを押してください。
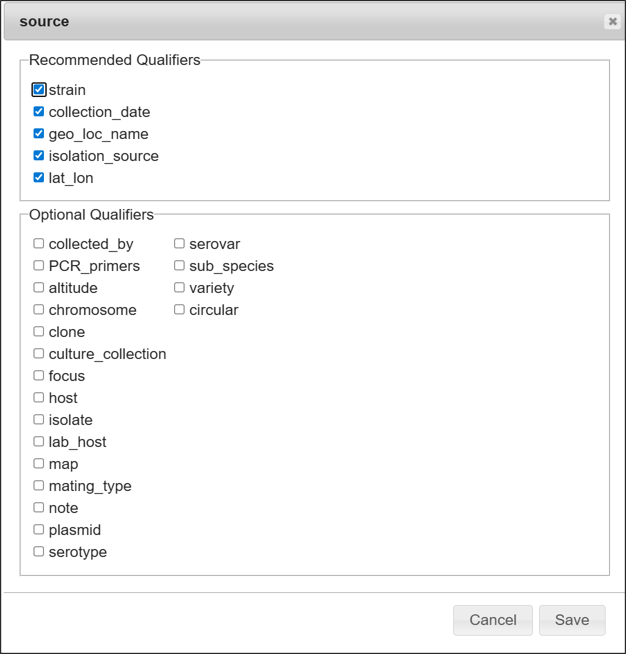
“Select qualifier”ボタン
追加したいqualifier横のチェックボックスにチェックを加えて、Saveをクリックすることでqualifierを追加できます。消す場合は、チェックを外してからSaveを押してください。選択可能なqualifierは、feature keyやtemplateの種類に応じて異なります。
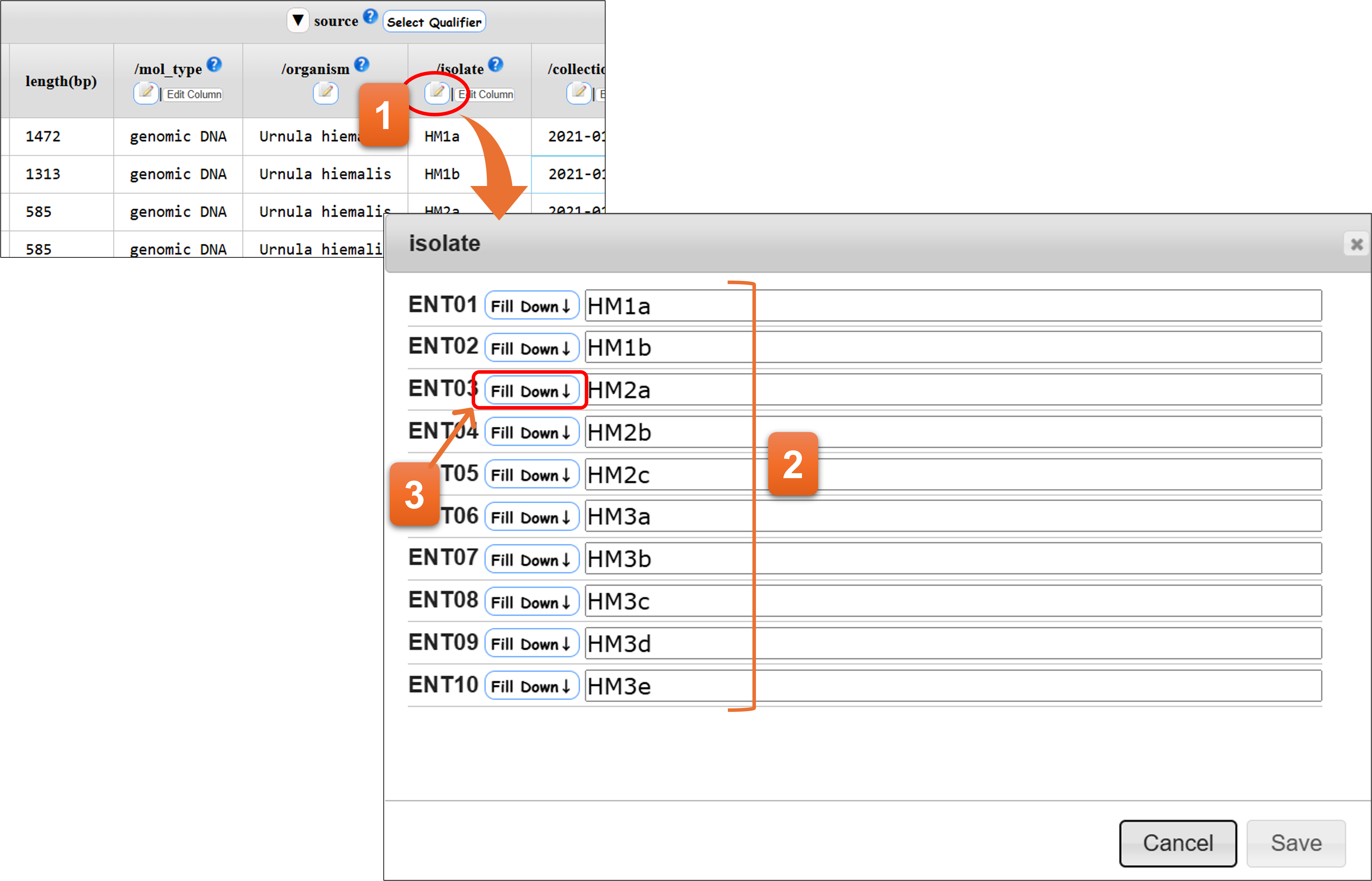
“Pen & Note”ボタン
テーブルの縦列ごとにqualifierの値を編集することができます。
- クリックします。
- ここで編集します。
- 以降のエントリーに同じ値をコピーしたい場合は、Fill Downをクリックします。
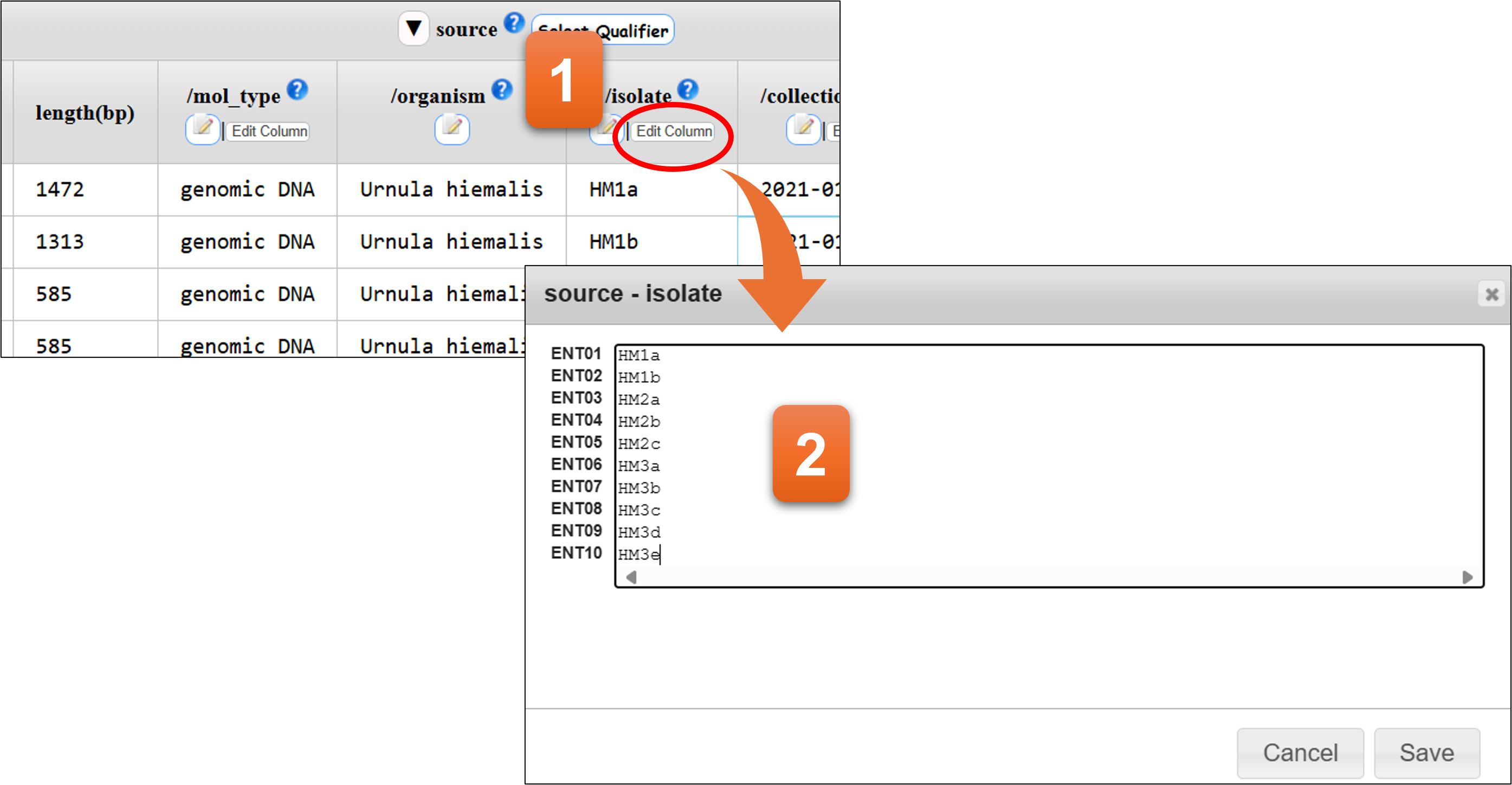
“Edit Colum”ボタン
テーブルの縦列ごとにqualifierの値を編集、複数列へのペーストが可能です。
- クリックします。
- テキストエリアに直接入力するか、エクセルやテキストエディタなどからコピーアンドペーストできます。エントリーごとに改行で区切ってください。
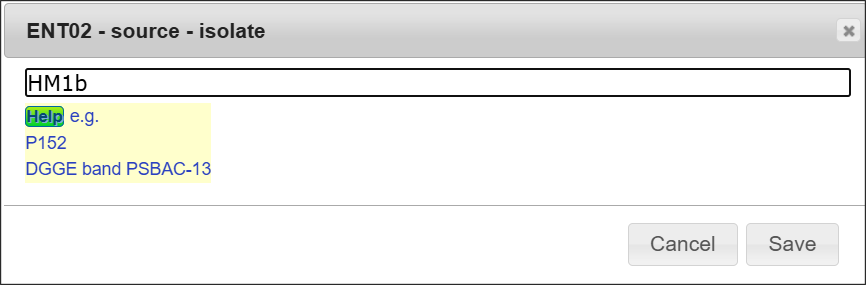
セルのダブルクリック
セルをダブルクリック(template - other選択時はqualifierまたはlocationのクリック)で入力欄が現れますので、値を修正または入力してください
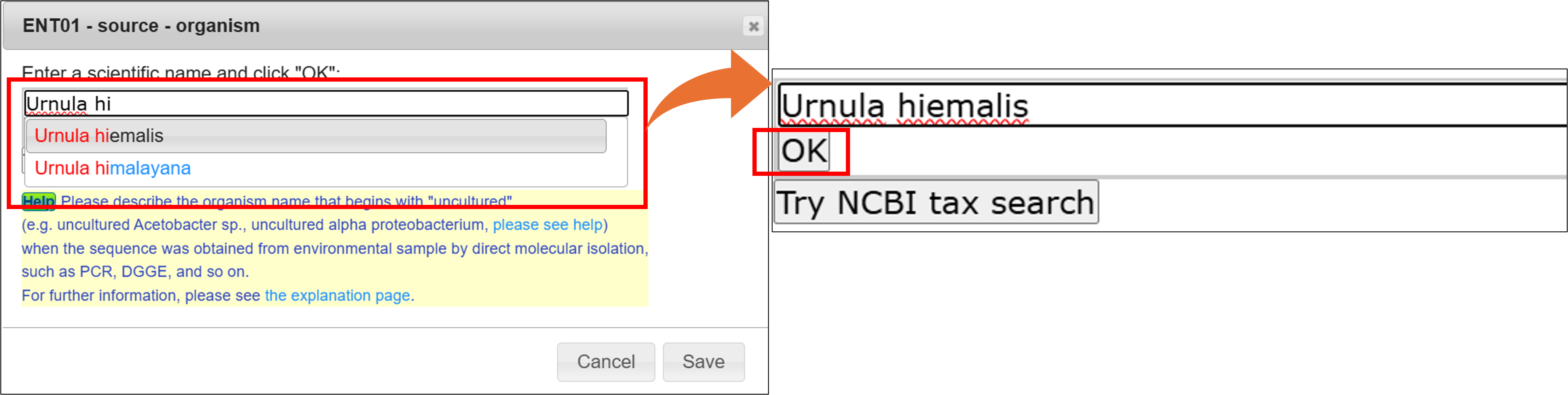
生物名 (Organism name)
生物名(学名)を入力します。タイプしていくと入力補助機能により候補の学名がリストされますので、リストからマウスで学名を選択、”OK”をクリックして確定します。
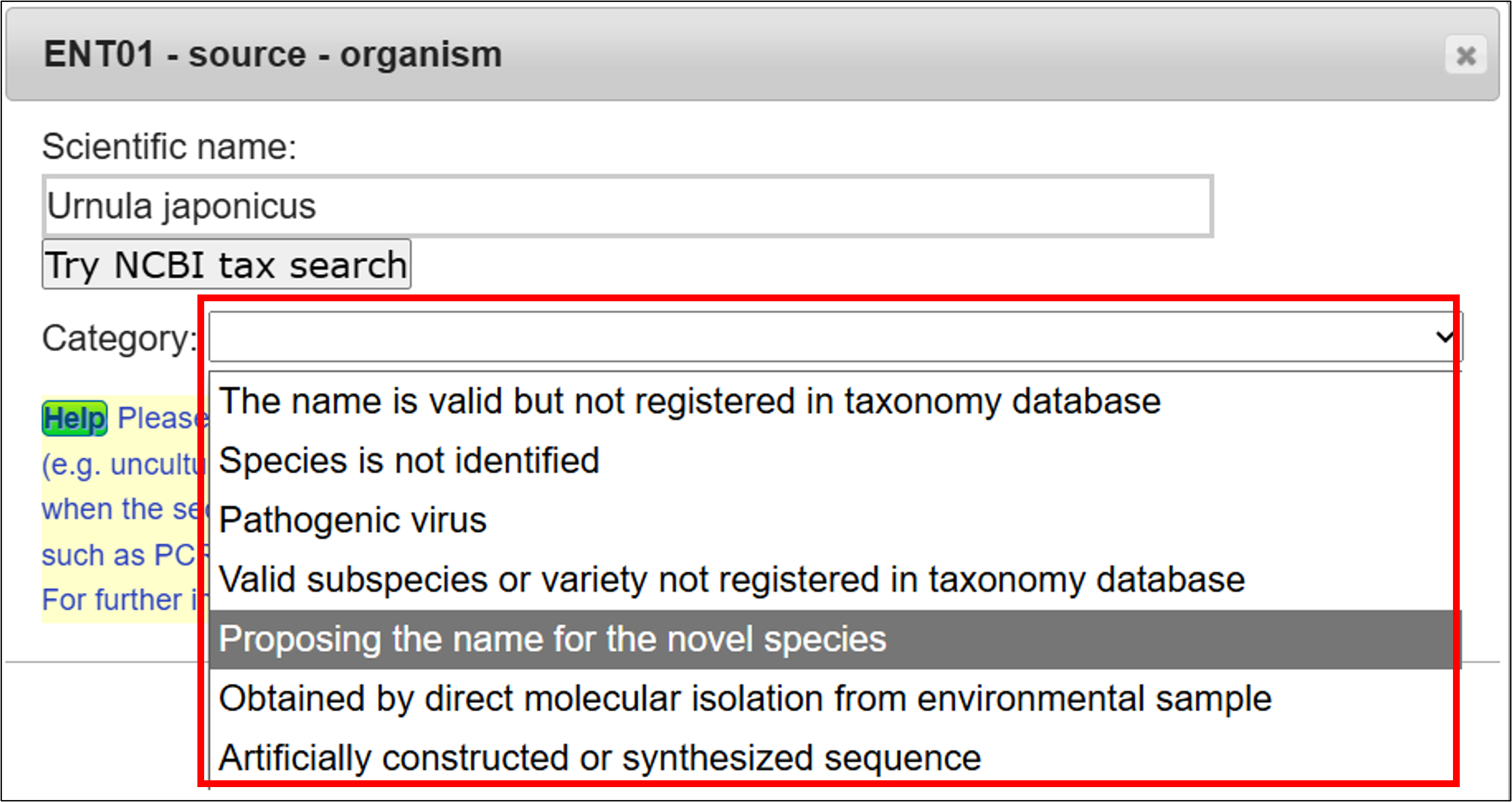
入力した名称が NCBI Taxonomy database に無い場合、Categoryリストから該当するカテゴリーを選択します。 詳細は、生物名入力におけるカテゴリ(Category)についてをご覧ください。
- 関連するページ
- Organism qualifier に記載する生物名
アノテーション例
16S rRNA
CDS
Mitochondrial cytb - tRNA-Pro
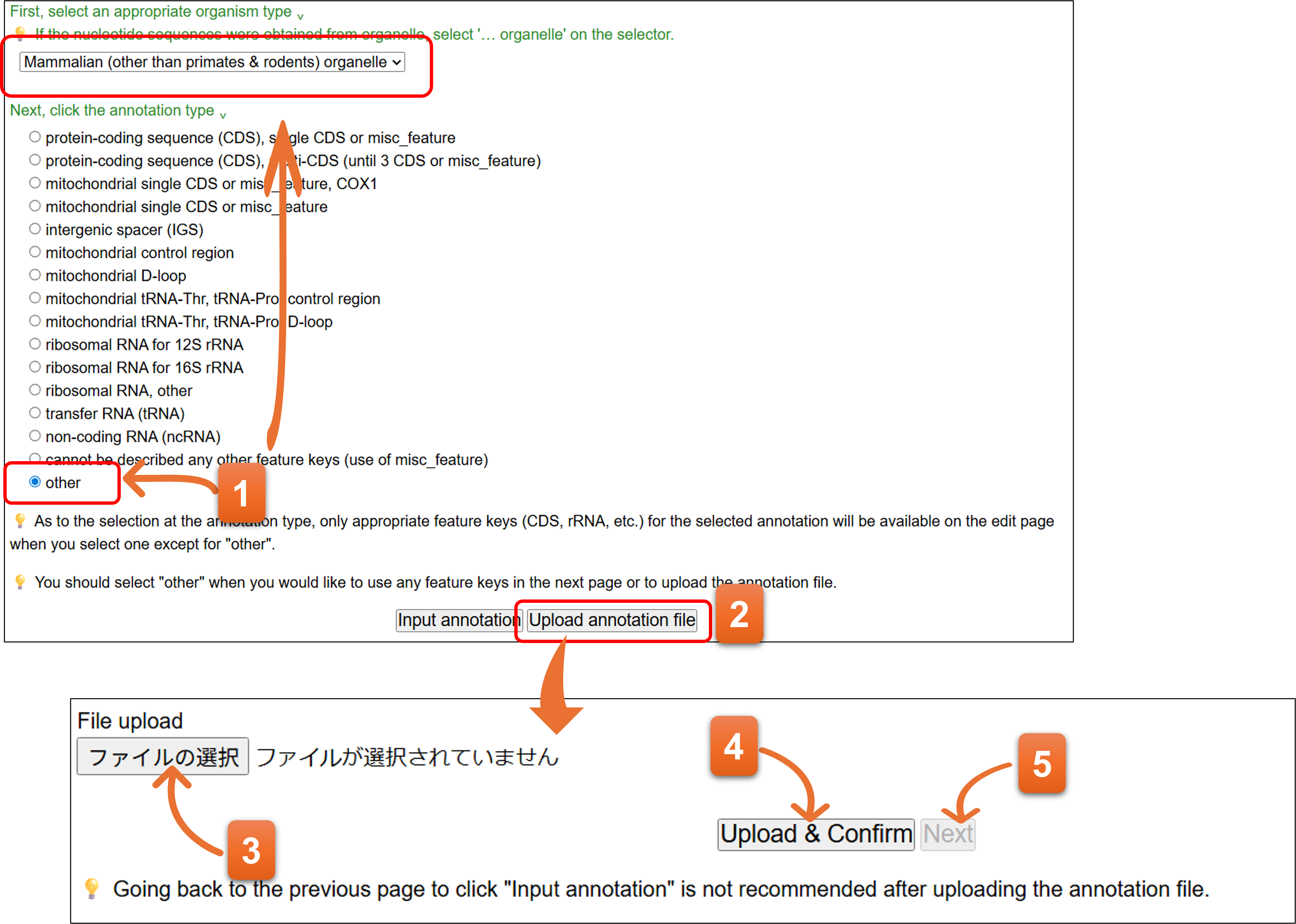
アノテーションファイルのアップロード方法
- テンプレート選択フォームにおいて、適切なtaxonomic divisionを選択し、アノテーションタイプには”other”を選択します。
- Upload annotation fileボタンをクリックします。
- クリックしてアノテーションファイルを指定します。
- アノテーションファイルをチェックするため、Upload & Confirmをクリックしてください。
- アノテーションファイルにエラーがある場合はクリックできません。アノテーションファイルを修正後、3と4を再度行います。エラーがなくなると”Next”が可能になるのでクリックしてください。
アップロード可能なアノテーションファイル
-
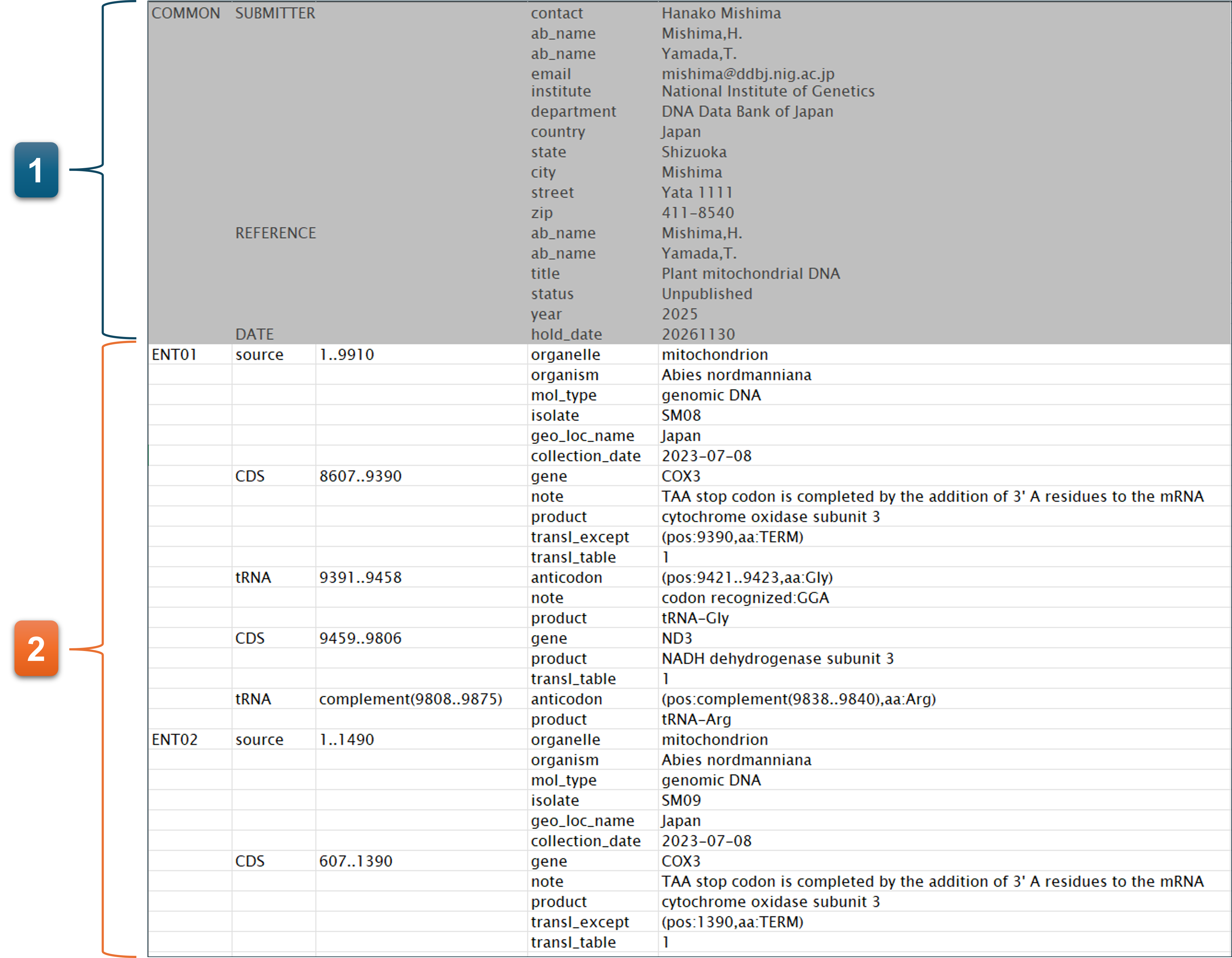
サンプルファイルをここからダウンロードできます。アノテーションファイルには、Biological Featureを含めてください。
-
アノテーションファイル作成方法に関する手引きは、登録ファイル形式、アノテーションファイルをご覧ください。
-
WGS、TSA、TLS、EST、HTC、GSS、STS、HTG 各アノテーション、TPA用アノテーション、DBLINKやST_COMMENTが記載されたアノテーションには対応していません。これらの登録については、Mass Submission System(MSS)をご利用ください。
-
アップロードされたアノテーションファイルの先頭には、”1. Contact person”、”2. Hold date”、”3. Submitter”、”4. Reference” に入力された内容が COMMON 情報として挿入されます。
-
“COMMON” を含むアノテーションファイルをアップロードした場合、COMMON は “1. Contact person”、”2. Hold date”、”3. Submitter”、”4. Reference” に入力された内容に置換されます。
- COMMONの部分は、アノテーションファイルに含まれていなくてもかまいません。アノテーションファイルに含めていたとしても、”1.Contact person”~”4.Reference”に入力した内容が使用されます。
- 各エントリーのBiological featureを記載します。
- 関連するページ
- Feature key の定義 / Qualifier key の定義 / Organism qualifier に記載する生物名 / タンパク質コード配列; CDS feature について
アノテーションファイルがアップロードエラーになる主な原因
-
エクセルを使用して作成した場合は、テキストエディタにコピーしてからテキストファイルとして保存してください。アノテーションファイルは、タブ区切りテキストファイルである必要があります。
-
“5. Sequence” で入力した配列名 (Entry name) をアノテーションファイルに入力していないか、入力順序が一致していない場合にはアップロードできません。
-
アノテーションファイルのタブ区切りで構成されるカラムが崩れている場合はアップロードできません。
-
余計なスペース、不正文字(全角文字、unicode文字、unprintable character)がファイル中に含まれている場合もアップロードできません。
-
source フィーチャーのみではアップロードできません。適切なフィーチャーを加えてください。
Error/Warning
-
“Confirm” クリック後、エラーが生じなければ、”Next” ボタンがクリック可能になり次のステップ(Final page)に進めます。
-
Error や Warning がある場合、アノテーション入力領域の下にメッセージが表示されます。
-
Error が生じた場合は、画面をスクロールアップしアノテーション入力領域におけるエラー対象エントリーを修正してください。
-
Submitter、Reference、Sequence に Error/Warning が生じた場合、画面上部にあるプログレスバー内の各ページをクリックし、修正してください。修正後は各ページにおいて “Next” ボタンをクリックした後、プログレスバーの “7.Annotation” をクリックすると Annotation 入力画面に戻ることができます。
-
Warning があっても、”Next” がクリック可能になります。Warning が生じた場合は入力内容を見直した上で、問題がある場合のみ修正してください。入力内容に問題がなければ “Next” をクリックしてください。
Error/warning メッセージの詳細については、Validator エラーメッセージをご覧ください。例のようにコード番号から直接リンクすることも可能です。
例:https://www.ddbj.nig.ac.jp/ddbj/validator.html#JP0015 …クリックしてから少し待っていただくと、該当エラー位置にスクロールします。
アミノ酸配列を得るには
CDS feature の翻訳アミノ酸配列 (/translation qualifier) を確認する方法を参考にしてください。
または以下の Web サービスを利用することで、塩基配列から翻訳されるアミノ酸配列を知ることができます。
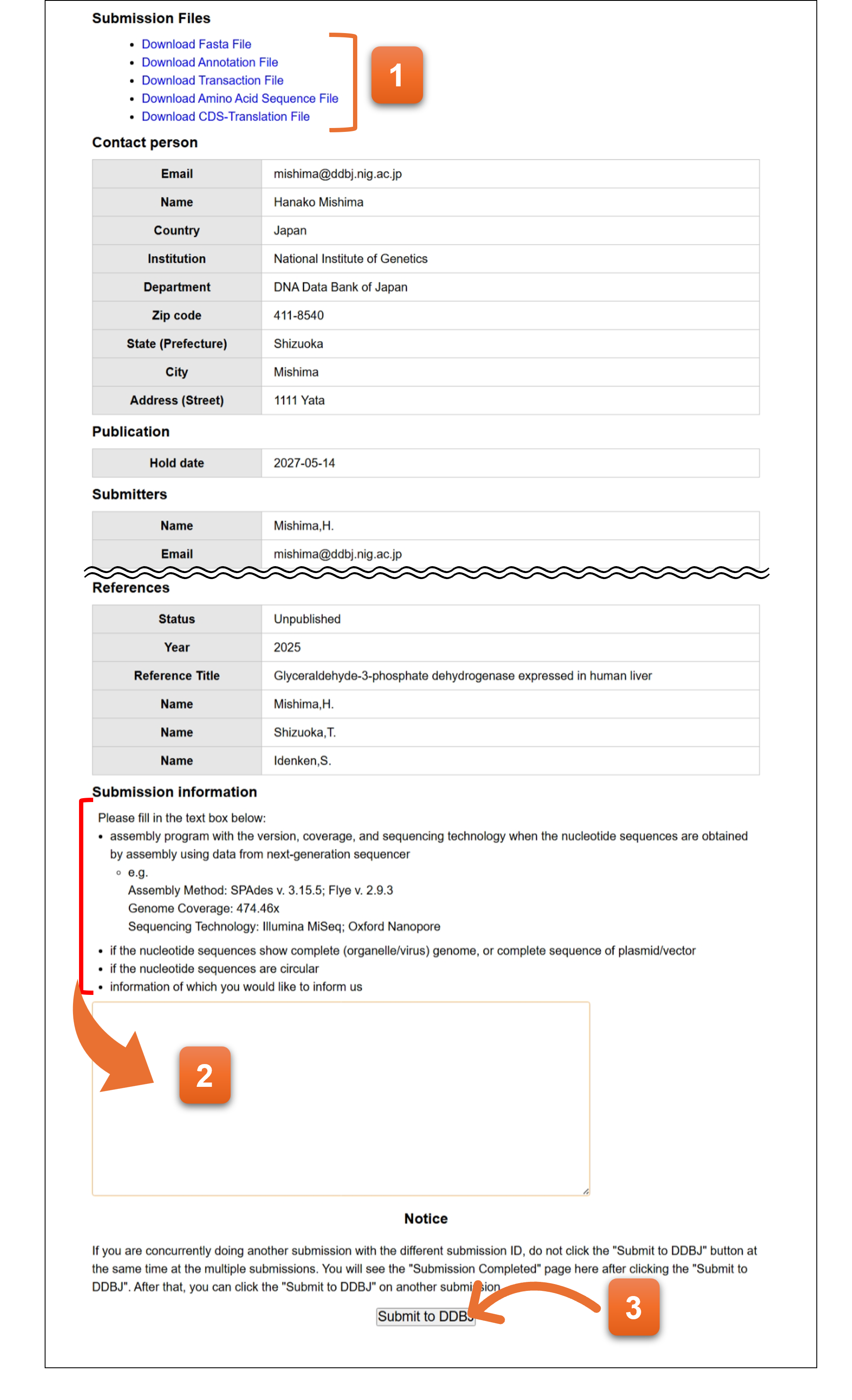
Final page
最終確認画面、および該当する場合には追加情報を入力します。
- ここまで各フォームに入力してきた内容をDDBJのアノテーションファイル、塩基配列ファイルの形式でダウンロードできます。
- ここに該当する項目がある場合、テキストエリアに記入をお願いします。
- クリックするとSubmission完了となります。Submission完了後、前のページに戻ることはできません。
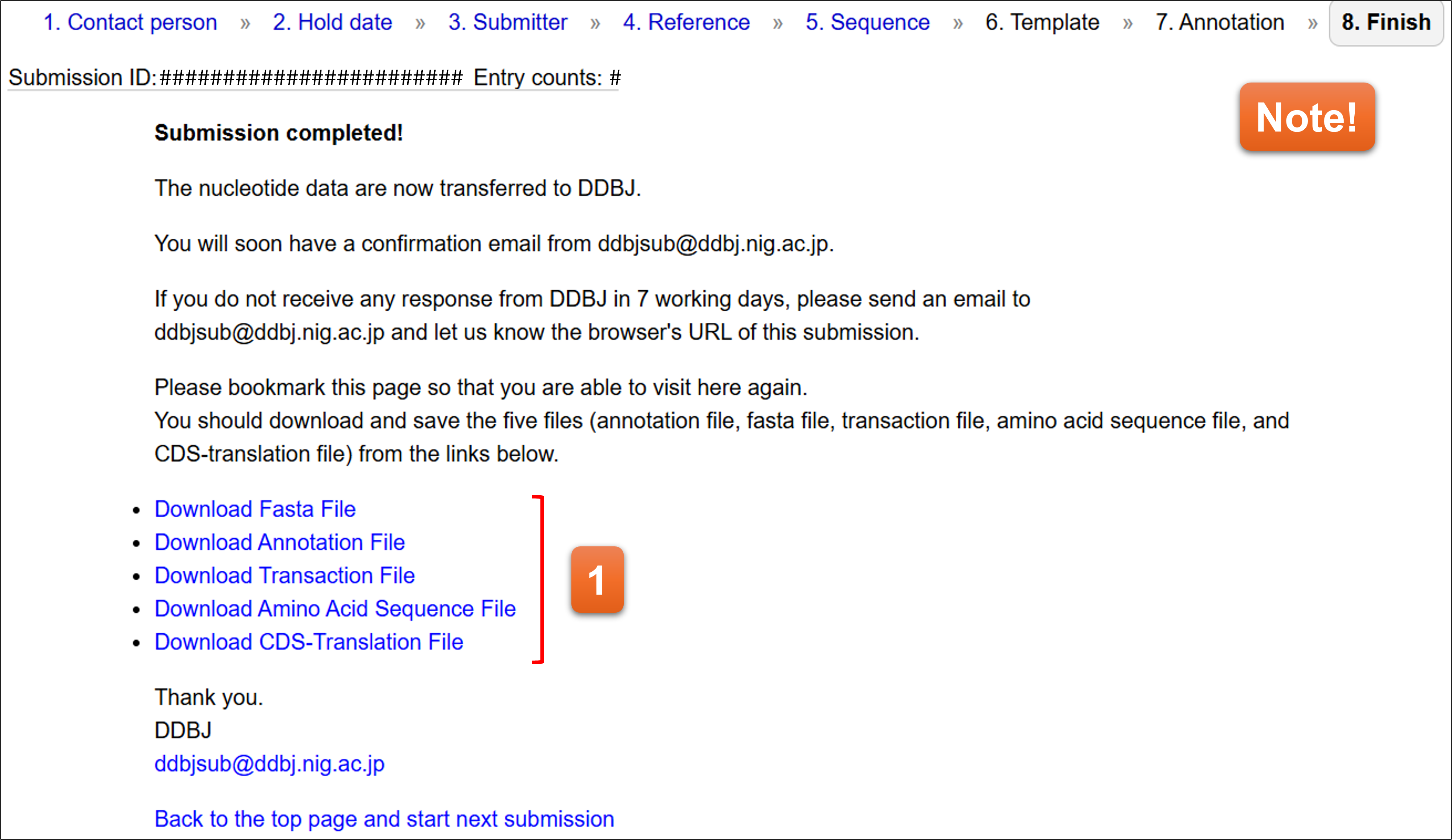
8. Finish
この画面が現れた時点でsubmission完了です。入力された内容は自動的にDDBJの登録用サーバーに転送されます。同時にSubmission完了を知らせるEmailがcontact personのアドレス宛に通知されます。
- 入力いただいた内容を、DDBJのアノテーションファイル、塩基配列ファイル形式でここからダウンロードできます。これらのファイルがDDBJ登録用サーバーに転送されます。
📌Note! このページをブックマークすることで、FinishページのみSubmission完了後から一定期間内は閲覧可能です。
登録完了メール